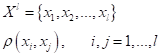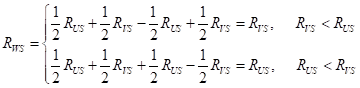|
Агломеративная иерархическая кластеризация. ДендрограммаПрактический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs Продолжаем рассматривать типовые алгоритмы кластеризации и на очереди алгоритм иерархической кластеризации. В чем суть такого подхода? Предположим, у нас имеется набор данных в числовом признаковом пространстве с заданной метрикой:
Для удобства я изображу их как точки в двумерном пространстве (хотя, в общем случае, пространство имеет n размерностей – по числу признаков). Далее, мы иерархически их либо объединяем, либо разбиваем на более мелкие кластеры. При объединении, изначально, каждый кластер содержит по одному объекту, а затем, на каждой итерации происходит объединение двух ближайших кластеров, образуя все более крупные группы. На практике, в основном используют идею последовательных объединений (агломерации) объектов. Отсюда и пошло название агломеративная иерархическая кластеризация. Одним из первых ученых, который предпринял такой подход к данным, был Карл Линней, который пытался по своей объемной картотеки растений и животных объединить их по родами и видам:
Полученные группы объектов, близких по определенным признакам, также называют таксонами. Фактически, таксон и кластер – это одно и то же и я буду использовать эти слова как синонимы. Давайте подробнее рассмотрим идею агломеративной кластеризации, как наиболее часто используемую на практике. Итак, изначально мы имеем набор данных и каждый объект – это независимый кластер. Затем, в соответствии с заданной метрикой между объектами:
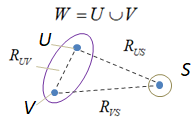
выбираем два ближайших таксона U, V и объединяем их в один W:
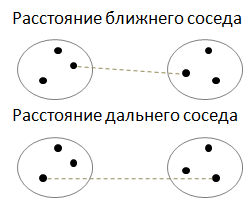
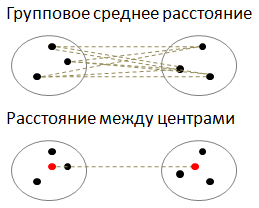
Этот шаг мы легко выполнили, так как умеем вычислять расстояния между отдельными объектами данных. Но теперь, у нас появилась группа из двух объектов. И нам нужно уметь вычислять расстояния от нее до всех остальных объектов выборки. Как это сделать? Тут имеется множество эвристик:
Так вот, оказывается, все эти варианты можно описать одной математической формулой:
где
Чаще всего на практике используют расстояние дальнего соседа и расстояние Уорда, т.к. они приводят, как правило, к лучшим результатам кластеризации. Давайте теперь детальнее разберемся, как работает формула Ланса-Уильямса. Проще всего показать ее принцип на одном объединенном таксоне W с двумя объектами и второго таксона S – с одним объектом:
Здесь отмечены все составляющие формулы. Предположим, что мы выбрали расстояние ближнего соседа, для которого:
и вычисление расстояния между кластерами W и S происходит, следующим образом:
Смотрите, если здесь раскрыть модуль, то получим:
А это есть не
что иное, как выбор минимального расстояния между точками таксонов. В итоге, мы
нашли расстояние между таксоном W и таксоном S. Потом, когда
нам придется таксон из двух объектов объединять с другим таксоном, то при
вычислении расстояния объединенного кластера W мы будем
использовать ранее вычисленное расстояние
То есть, U, V и S здесь могут быть не только отдельными точками, но, по мере объединения (работы алгоритма), и кластерами с произвольными числом точек. Благодаря рекуррентному вычислению расстояний между объединяемыми таксонами и всеми остальными, мы, на каждой итерации алгоритма, имеем полную информацию о расстояниях между любыми парами сформированных кластеров. Вот это ключевой
момент работы алгоритма агломеративной иерархической кластеризации. По аналогии
работают и все остальные метрики с другими значениями коэффициентов В результате, получаем следующий алгоритм иерархической кластеризации: 1:
2: для
всех
3: найти в 4: объединить их в один кластер: 5: для всех 6: вычислить
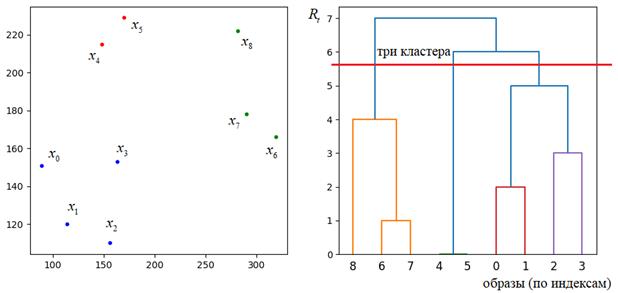
Реализовать данный алгоритм на языке Python с помощью пакета SkLearn можно, следующим образом: Здесь создается объект класса AgglomerativeClustering: clustering = AgglomerativeClustering(n_clusters=NC, linkage="ward", metric="euclidean") которому передается число итоговых (выходных) кластеров, способ вычисления расстояний между кластерами и метрика для исходных данных (объектов). А, затем, алгоритм применяется ко входным данным: x_pr = clustering.fit_predict(x) На выходе получаем NumPy массив из набора объектов, сгруппированных по кластерам. Подробную документацию по этим и другим параметрам можно почитать на странице официальной документации: https://scikit-learn.org/stable/modules/generated/sklearn.cluster.AgglomerativeClustering.html ДендрограммаДля визуализации процесса иерархической кластеризации и оценки ее качества часто строят график специального вида, который получил название дендрограмма.
По вертикали
откладывается минимальное расстояние Хороший алгоритм иерархической кластеризации должен давать дендрограмму без внутренних пересечений и с ярко выраженными минимальными отступами между формируемыми кластерами. Дендрограмма на рисунке соответствует этим критериям. Конечно, при выборе других метрик и способов вычисления расстояний между кластерами, дендрограмма будет меняться. Кроме оценки качества этот график показывает нам, где можно провести уровень отсечения для получения определенного числа выходных кластеров. Это очень удобно, особенно, если мы наперед не знаем, на сколько таксонов следует разбить входные данные. Дендрограмма может помочь увидеть явные различия между разными группами на разных уровнях иерархии. Итак, общее заключение здесь можно сделать, следующее:
Рекомендации по агломеративной иерархической кластеризации1. При выборе метрики расстояний между кластерами лучше начать с расстояния Уорда (Ward), а затем пробовать другие, например, часто следующим берут расстояние дальнего соседа. 2. Строят несколько вариантов кластеризаций (с разными метриками) и по дендрограмме выбирают лучший вариант (чисто визуально). 3. Результирующее
число кластеров определяют по уровню, где максимально изменение минимального
расстояния Практический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs Видео по теме |