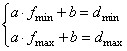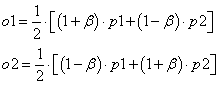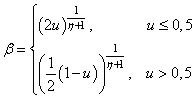|
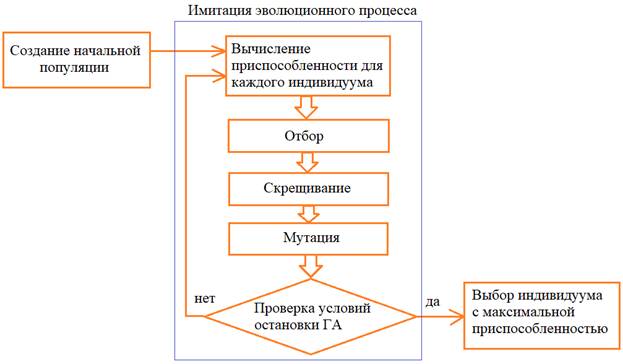
Обзор методов отбора, скрещивания и мутацииНа этом занятии мы с вами рассмотрим основные подходы к реализации операторов отбора, скрещивания и мутации, которые составляют основу любого ГА:
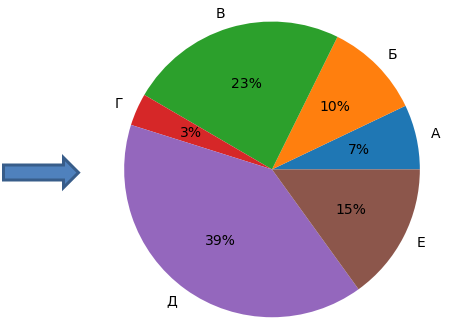
Методы отбораНачнем с обзора методов отбора лучших хромосом в популяции. Напомню, что на этом этапе отбираются наиболее приспособленные особи, которые становятся «родителями» для формирования следующего поколения. Но, при этом, необходимо сохранить возможность и менее приспособленным особям давать незначительное количество своих потомков для сохранения разнообразия генофонда. Правило рулеткиМетод отбора по правилу рулетки, или отбор пропорциональной приспособленности (fitness proportionate selection – FPS), заключается в случайном выборе индивидуума из популяции пропорционально его приспособленности. Предположим, у нас имеется несколько особей в популяции с разной степенью адаптации:
Тогда их можно условно представить на круговой диаграмме с секторами, размером соответствующих долей:
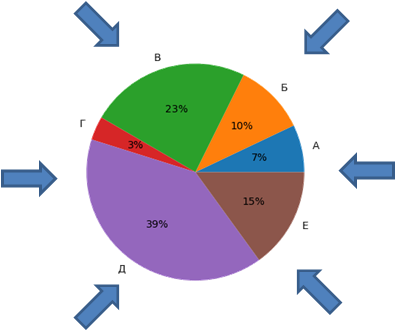
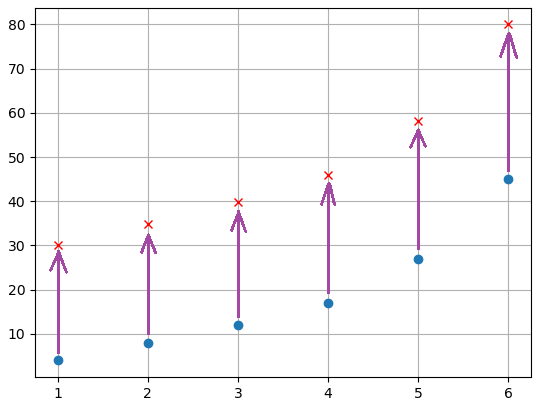
Затем, мы раскручиваем этот круг и тот сектор, на который будет указывать стрелка, будет выбран. Таким образом, отбирается особь в качестве родителя. Очевидно, что чаще (с наибольшей вероятностью) будут отбираться индивидуумы с большей приспособленностью, так как у них сектор занимает большую долю. Стохастическая универсальная выборкаСтохастическая универсальная выборка (stochastic universal sampling – SUS) – модифицированный вариант рулетки, когда точки отбора (стрелки) располагаются равномерно вокруг диаграммы:
Вращение выполняется один раз и сразу производится отбор всех особей для дальнейшей операции скрещивания. Преимущество этого подхода в том, что он гарантирует отбор не только индивида с большой долей сектора, но, скорее всего, будут отобраны и другие особи с меньшими секторами. То есть, выбор более равномерен и сохраняет, в некоторой степени, разнообразие популяции. Ранжированный отборСледующий метод ранжированного отбора работает похожим образом на правило рулетки, но доли для индивидуумов вычисляются несколько иначе. Вначале все индивидуумы ранжируются (упорядочиваются) по возрастанию их приспособленности (см. столбец «Ранг»):
Затем, вычисляются доли относительно ранга (а не приспособленности, как в правиле рулетки) и, тем самым, доли секторов становятся более равномерными, а значит, более равномерно будут отбираться родители из популяции:
Этот подход дает хорошие результаты когда в популяции имеются отдельные особи с высокой приспособленностью. Тогда, чтобы они не «захватили» всю популяцию, отбор лучше делать по рангу, а не по приспособленности. Также этот способ позволяет отбирать лучших претендентов, когда приспособленности особей в популяции примерно одинаковы. Тогда ранг позволит с заметно большей вероятностью отбирать самых лучших, сохраняя отбор менее приспособленных. Масштабирование приспособленностиРазвитие идеи ранжированного отбора привело к способу масштабированного отбора. Здесь вместо рангов исходные значения приспособленности масштабируются к заданному интервалу значений. Например, у нас имеются особи с функцией принадлежности, равной:
И мы все эти значения от 4 до 45 хотим перевести в новый диапазон [30; 80]. Это делается простой математической операцией:
где a, b – коэффициенты преобразования (линейной функции); f – значение приспособленности особи. Найти коэффициенты a, b очень просто, зная величину нового диапазона [30; 80]. Мы можем сформировать два уравнения для граничных точек:
где Из этой системы линейных уравнений, находим коэффициенты a и b:
Для нашего конкретного случая эти коэффициенты, равны:
Отображение прежних значений f в новый диапазон f*, показано на рисунке ниже:
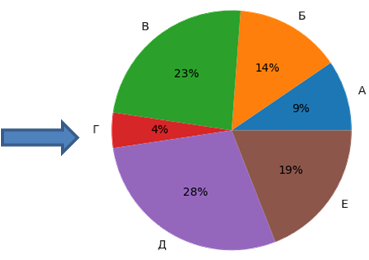
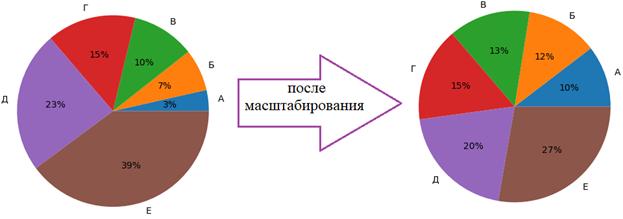
Что нам это в итоге дает? Смотрите, как меняется распределение долей секторов после операции масштабирования:
Благодаря этому, особи отбираются из популяции более равномерно, и у худших появляется реальный шанс оказаться в новой выборке и тем самым обеспечить разнообразие хромосом. С другой стороны, хорошо приспособленные особи не заменяют собой новую популяцию, а всего лишь с большей вероятностью отбираются наряду с остальными претендентами. Все это благотворно влияет на сходимость ГА к оптимальному или близкому к оптимальному решению. Турнирный отборО турнирном отборе мы с вами уже говорили на одном из прошлых занятий. Идея очень проста, но вместе с тем, эффективна. Каждый раз из популяции случайным образом отбирается несколько претендентов (от двух и более). Затем, среди отобранных участников выбирается наиболее приспособленный (с наибольшим значением функции принадлежности). Он и переходит в новую выборку.
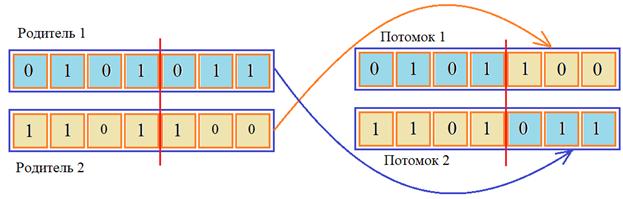
Процесс повторяется до тех пор, пока число «родителей» не станет равно размеру популяции. Последнее время турнирному отбору отдается все больше предпочтений. Он решает проблему отбора наименее приспособленных особей, сохраняя разнообразие популяции, и позволяет вообще обходиться без функции принадлежности. Здесь достаточно уметь сравнивать приспособленность особей между собой. В некоторых трудноформализуемых задачах это особенно полезно. Как же из всего этого разнообразия подходов выбрать наиболее эффективный для решения конкретной задачи с помощью ГА? К сожалению, ответа на этот вопрос нет. Это, как раз, пример трудноформализуемой задачи. Здесь на первый план выходит опыт разработчика таких алгоритмов и, конечно же, здравый смысл. Но, рекомендация очень простая: начинайте с турнирного отбора, а если результаты кажутся неудовлетворительными, то пробуйте другие способы. Методы скрещиванияСкрещивание (также называется кроссинговер и кроссовер) следующая базовая операция в генетическом алгоритме. Здесь перебираются пары родителей (как правило, без повторения) из отобранной популяции и с некоторой высокой вероятностью выполняется обмен фрагментами генетической информации для формирования хромосом двух потомков. Если родители не участвовали в скрещивании, то они переносятся (копируются) в следующее поколение. Одноточечное скрещиваниеВ самом простом варианте операция кроссинговера выполняет обмен между двумя половинками хромосом родителей для формирования хромосом потомков.
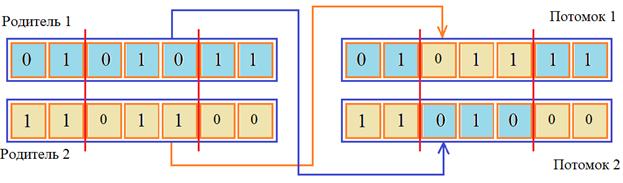
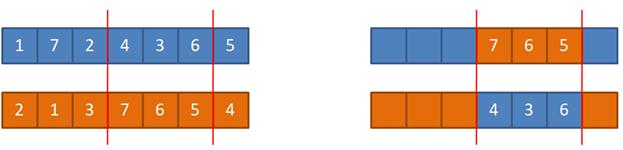
Вначале случайным образом определяется точка разреза хромосомы, а затем, соответствующие части меняются местами. Получаются две новые хромосомы для двух потомков. Двухточечное и k-точечное скрещиваниеОднако, как показывает практика, двухточечное скрещивание дает лучшие результаты, чем одноточечное. При двухточечном кроссинговере вместо одной точки разреза выбираются две случайным образом (разумеется, они не должны попадать на границы хромосом и совпадать между собой). Принцип работы двухточечного скрещивания демонстрируется следующим рисунком:
А реализовать его можно с помощью двух одноточечных операторов скрещивания. Сначала делается обмен частями хромосом по первой точке разреза, а затем, - по второй. Аналогично можно реализовать и k-точечное скрещивание. Равномерное скрещиваниеСледующая идея скрещивания заключается в формировании потомков из скрещивания отдельных пар ген родителей, которые отбираются из хромосом случайным образом. Здесь слово «равномерное» означает использование датчика равномерного распределения для определения случайной позиции генов в хромосоме. В самом простом варианте можно проходит по генам обоих родителей и с некоторой заданной вероятностью менять их местами:
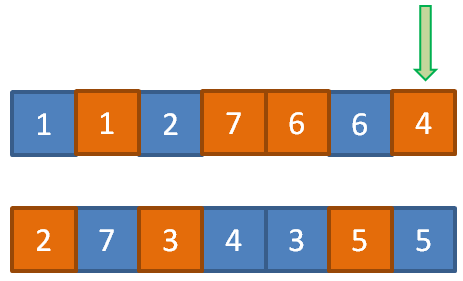
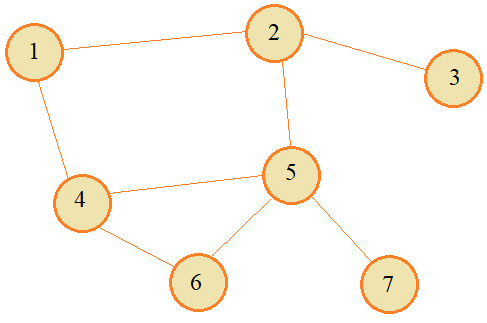
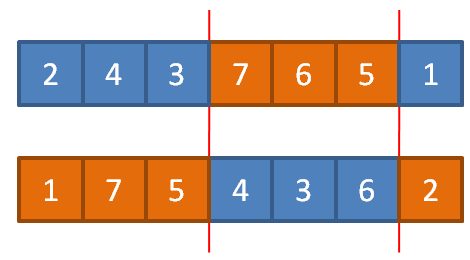
Но, в общем случае, произвольно выбирается ген у родителя 1, затем, у родителя 2 и производится их обмен. Упорядоченное скрещиваниеВ предыдущем примере хромосомы родителей состояли из неповторяющихся чисел от 1 до 7, но после скрещивания мы получили потомков, у которых некоторые числа стали совпадать. В некоторых случаях такой результат является недопустимым. Например, если с помощью ГА решается задача поиска кратчайшего пути обхода всех городов, которые условно заданы числами от 1 до 7 и соединены магистралями в виде следующего графа:
У каждого участка маршрута между двумя соседними городами имеется определенная длина. И эту суммарную длину необходимо минимизировать. Так формулируется известная задача коммивояжера. В ней каждый потомок должен всегда содержать наборы чисел от 1 до 7 в своих хромосомах и потеря этой информации считается недопустимой. Как раз для таких случаев был предложен способ упорядоченного скрещивания хромосом родителей. Идея его очень проста. Вначале делается уже известный вариант скрещивания, который не приводит к дублированию чисел, например, частый случай двухточечного скрещивания:
А оставшиеся значения генов у потомков заполняем следующим образом. Мы проходим все гены первого родителя, начиная от второй точки разреза, и добавляем значения, если они не еще не присутствуют в хромосоме первого потомка. Затем, ту же самую операцию выполняем со вторым родителем и вторым потомком. В результате, получим следующий набор генов у двух потомков:
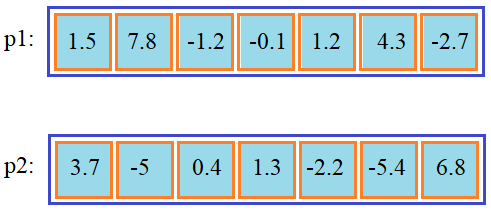
Вообще, все эти алгоритмы перемешивания генов в потомках – творческий процесс и каждый из вас вполне может придумать свой собственный вариант и, кто знает, возможно, он окажется удачным для решения определенных задач. Скрещивание смешениемВ случаях, когда гены содержат вещественные значения можно воспользоваться способом под названием скрещивание смешением (blend crossover – BLX). Его идея достаточно проста. Вначале выбираются два родителя, условно обозначим их p1 и p2 с набором определенных генов:
Затем, последовательно перебираем соответствующие пары ген этих двух родителей и вычисляем интервал для последующей генерации случайных значений генов потомков. Интервал определяется формулой:
где
Здесь всюду
полагалось, что p1 < p2. При Далее, в интервале [d1; d2] случайным образом выбираются два числа: для первого и второго потомков. И так для всех генов. На выходе получаем двух потомков с новым набором ген. Имитация двоичного скрещиванияИдея имитации двоичного скрещивания (simulated binary crossover – SBX) заключается в имитировании свойств одноточечного скрещивания, применяемое в двоичных хромосомах (состоящих из 0 и 1). Ключевой особенностью здесь является равенство среднего значения хромосом у родителей и у потомков. Гены двух потомков вычисляются по следующим формулам:
где Смотрите, если Величину
Значение u генерируется как
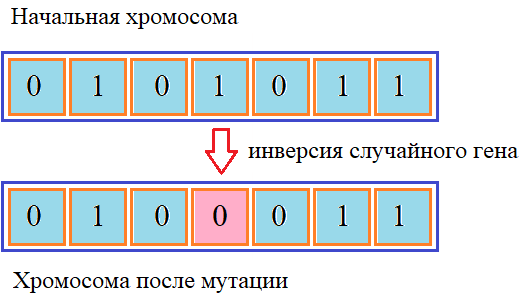
равномерная случайная величина в диапазоне [0; 1], а параметр Методы мутацииПоследний оператор, который применяется для формирования нового поколения популяции – это мутация. Обычно, она применяется с некоторой малой вероятностью к отдельным генам потомков, меняя их определенным образом. Мутация позволяет поддерживать генетическое разнообразие особей, чтобы популяция не выродилась и хромосомы не стали похожи друг на друга. Инвертирование битовНаверное, самый простой вариант мутации – это инвертирование битов, записанные в генах. Здесь может быть несколько вариантов реализации. Например, с некоторой (обычно низкой) вероятностью хромосома подвергается мутации и далее случайный бит (ген) переводится и инверсное состояние:
Либо, можно вначале также выбираем с некоторой вероятностью хромосому для операции мутации, а затем, проходим по всем генам и с некоторой другой (также низкой) вероятностью выполняем инверсию бит. Мутация обменомДля упорядоченных списков (когда в генах хромосомы хранятся индексы некоторого списка и они не должны повторяться, как в задаче коммивояжера) можно выполнять мутацию путем обмена случайно выбранных генов:
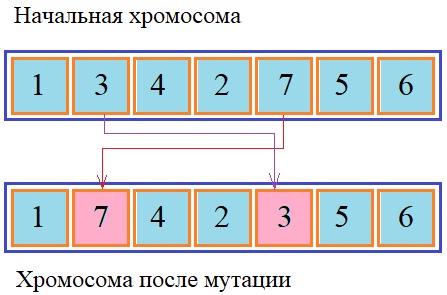
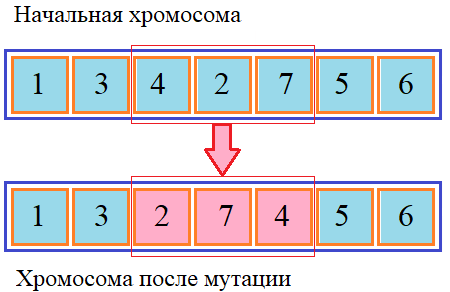
Этот же способ мутации можно использовать и в других типах задач, не обязательно только для списков. Мутация обращениемНесколько видоизмененная идея мутации обменом является другой способ – мутация обращением. Здесь мы выбираем также случайным образом непрерывную последовательность генов, которые, затем, записываем в обратном порядке:
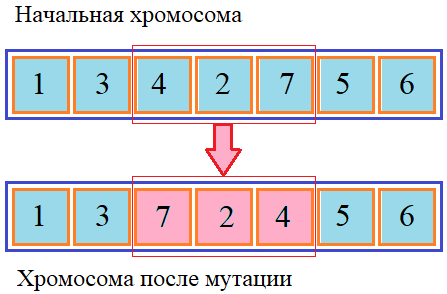
Этот метод также пригоден при кодировании списков в генах, так как данные не искажаются, а лишь меняются местами. Мутация перетасовкойНесколько более разнообразные результаты мутации можно получить, если в предыдущем алгоритме значения ген записывать не в обратном, а случайном порядке. Такой подход известен под названием мутация перетасовкой:
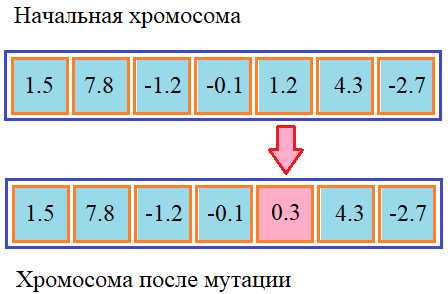
Мутация для вещественных чиселЕсли в генах хранятся вещественные числа, то помимо рассмотренных подходов (кроме, может быть инвертирования битов), можно воспользоваться еще одним, связанным с генерированием случайных вещественных величин. Например, можно вначале определить с некоторой небольшой вероятностью ген, который будет подвергаться мутации, а затем, в него записать новое случайное значение:
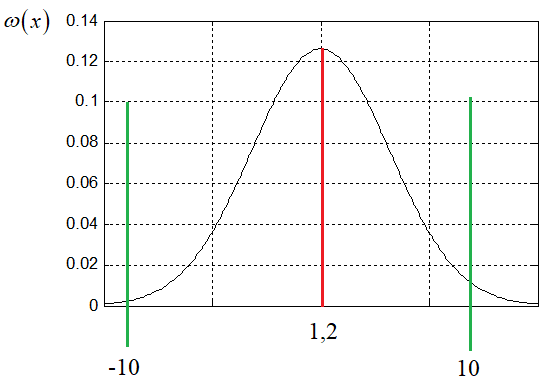
И здесь возникает один тонкий момент. Числа следует генерировать, во-первых, из области допустимых значений и, во-вторых, желательно близкими к исходному значению. Например, если мы знаем, что допустимый диапазон значений [-10; 10], то новое значение для прежнего гена с числом 1.2 можно смоделировать с помощью нормального закона распределения:
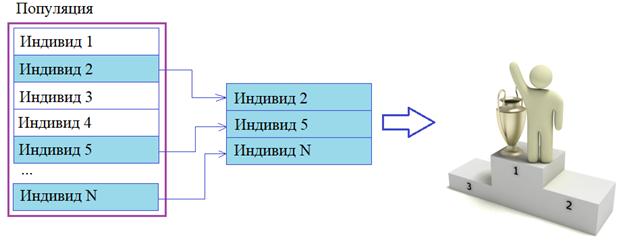
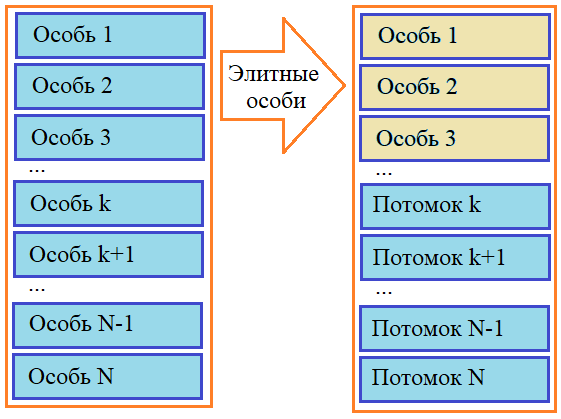
Здесь в качестве среднего значения (математического ожидания) берется, как раз величина 1,2 и ограничивается диапазоном [-10; 10]. На языке Python выполнить такое моделирование очень просто. Для этого можно воспользоваться функцией triangular(), которая ограничивает диапазон СВ [-off; off] и функцией gauss(), которая моделирует нормальные (гауссовские) случайные величины с заданным средним mu и стандартным отклонением sigma: x = random.triangular(-off, off, random.gauss(mu, sigma)) ЭлитизмВ заключение этого занятия отметим еще один механизм, применяемый совместно с оператором отбора в ГА – элитизм. Его смысл очень прост. В следующее поколение мы гарантированно отбираем небольшое число наиболее приспособленных (элитных) особей:
Причем, эти элитные индивидуумы также участвуют в скрещивании на правах родителей. Такой подход позволяет сохранять в популяции лучшие решения (не теряя их и не переоткрывая заново). В ряде задач это существенно увеличивает скорость сходимости ГА к некоторому приемлемому или оптимальному решению. Вот так в целом можно выполнять операции отбора, скрещивания и мутации в генетических алгоритмах. Опять же, какой метод выбрать, зависит от типа решаемой задачи и от опыта разработчика ГА. Поддержка методов отбора, скрещивания и мутации пакетом DEAPВ пакете DEAP уже реализованы многие из представленных методов отбора, скрещивания и мутации. Подробно о них можно посмотреть в официальной документации: https://deap.readthedocs.io/en/master/api/tools.html#module-deap.tools Ниже в таблицы перечислены все эти встроенные методы:
Кроме того, вы всегда самостоятельно можете реализовать свои собственные методы и встроить в ГА, реализуемый с помощью DEAP. Видео по теме |