|
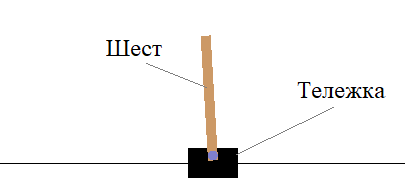
Не дай шесту упасть или как нейросеть держит балансАрхив проекта: ga_11.zip Пришло время наделить наши алгоритмы зачатками интеллекта и заставить программу держать баланс подвижного шеста, управляя тележкой:
Ее можно перемещать только в горизонтальной плоскости (вправо, влево), удерживая шест в вертикальном состоянии. Изначально он немного наклонен, так что стоять на месте не получится. Для моделирования такого виртуального окружения, мы также можем воспользоваться пакетом OpenAI Gym, используя уже известную нам команду: import gym env = gym.make('CartPole-v1') Для инициализации окружения используется метод reset(), а для передачи команд на каждой итерации – метод step(): observation = env.reset() observation, reward, done, info = env.step(action) Объект observation содержит четыре вещественных числа:
За каждый шаг, при котором стержень не падает (отклонился от вертикали менее чем на 15°), назначается вознаграждение reward = 1.0. Соответственно, эпизод заканчивается, если:
Цель алгоритма, не дать стержню упасть на протяжении 500 шагов. То есть, максимальное вознаграждение равно 500 единиц. Чтобы достичь этой цели, нужно уметь правильно генерировать команды для тележки в зависимости от состояния шеста:
Нейросетевой контроллерКак будем решать эту задачу? Если воспользоваться идеей предыдущего занятия и хранить в хромосоме 500 команд для перемещения тележки на каждом шаге:
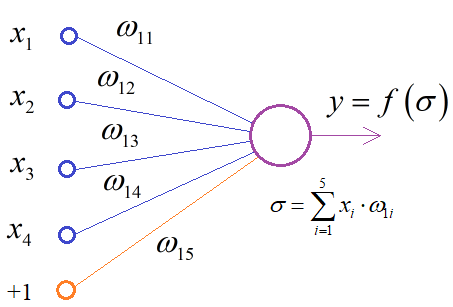
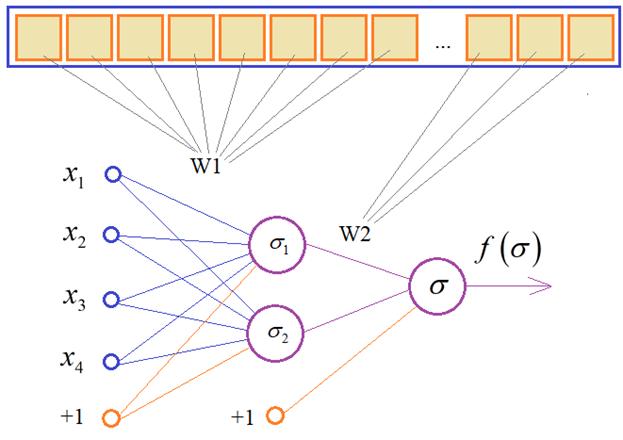
то ничего не получится, так как начальный наклон шеста в каждом эпизоде разный, а это значит, что при каждом новом запуске виртуального окружения перемещения будут различаться, чтобы успешно удерживать баланс шеста. Здесь нужен более изощренный подход – использование нейронной сети, а точнее, - создать нейросетевой контроллер, который бы вырабатывал команды 0 и 1 в зависимости от входных данных окружающей среды (объекта observation): положение тележки; скорость тележки; угол наклона шеста; скорость кончика шеста. Нейронные сети очень хорошо подходят для решения подобных задач, когда нужно некие входные данные отобразить в заданные выходные. В нашей достаточно простой задаче вполне рабочей будет конфигурация НС с четырьмя входами и одним выходом:
Здесь величины
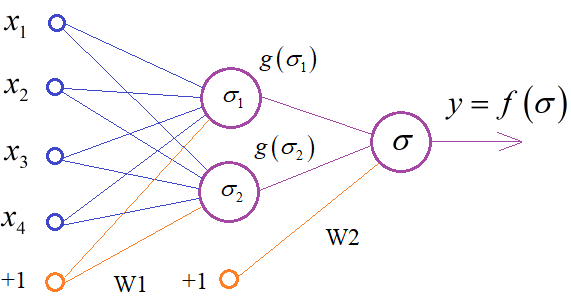
Если все это вам кажется сложным и непонятным, то смотрите плейлист по нейронным сетям: https://www.youtube.com/watch?v=nV7cI5zgOpk&list=PLA0M1Bcd0w8yv0XGiF1wjerjSZVSrYbjh Там подробно рассказывается о принципах работы разных типов НС и приведены многочисленные примеры. Конечно, вместо простейшей архитектуры НС, можно взять и что-то посложнее, например, такую:
Здесь появляется
еще один скрытый слой из двух нейронов с другой функцией активации
Соответственно, число весовых коэффициентов заметно возрастает. Но, могу сразу сказать, что это избыточная структура. С точки зрения теории автоматического управления, достаточно простейшей НС с одним выходным нейроном. И как показывает практика, она работает. Генетический алгоритм и нейронные сетиУ многих из вас, возможно, остается вопрос, как выбирать значения весовых коэффициентов в нейронной сети? Это самый главный и ключевой вопрос не только этой задачи, но и во всей теории НС. Здесь мы имеем случай, когда нет набора обучающих данных, а есть только внешняя среда и агент (тележка), которым мы можем управлять. Как в такой ситуации обучать НС (то есть подбирать весовые коэффициенты)? Здесь нам на помощь приходит концепция обучения с подкреплением, когда верное поведение вознаграждается, а неверное – наказывается. Верное поведение в нашей задаче – это удержание шеста в вертикальном положении. И за каждый шаг, пока он не упал, агенту начисляется вознаграждение +1 балл. Это, как раз то, что поможет нам проводить обучение НС. Мы будем подбирать весовые коэффициенты так, чтобы вознаграждение в каждом эпизоде было максимальным.
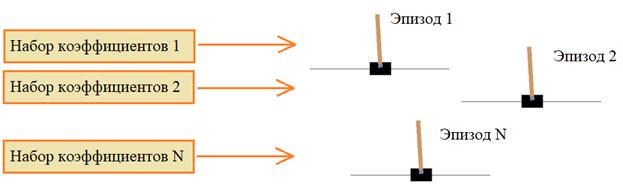
То есть, предположим, что начальные весовые коэффициенты выбираем случайным образом в диапазоне [-1; 1]. Далее, для каждого набора запускаем виртуальное окружение и смотрим, как долго продержится шест в вертикальном положении под управлением нейронной сети. Наборы, при которых шест держится дольше, считаются наилучшими. Их следует отбирать и улучшать. Так мы будем моделировать процесс эволюции нейросетевых контроллеров с помощью генетического алгоритма. Как видите, в задачах, где сложно выстроить математический аппарат для оптимизации данных (весовых коэффициентов), хорошо подходят эволюционные алгоритмы, в частности, ГА. Это тот случай, когда его использование оправдано и часто применяется в подобных задачах. Фактически, здесь, мы имитируем эволюционное развитие особей, каждая из которых специализируется на управлении тележкой. Это очень напоминает природный процесс, когда эволюция оттачивает поведение живых организмов и оставляет лучших. Кодирование хромосомСейчас мы с вами выступим в роли бога и создадим мир развития нейросетевых существ, управляющих тележкой. Биология подсказывает нам, что поведение и развитие живых существ заложено в молекуле ДНК, в частности в хромосоме с набором генов. Именно с кодирования хромосом мы и начнем реализацию ГА.
Как вы уже, наверное, догадались, в хромосомах индивидуумов мы будем хранить весовые коэффициенты выбранной архитектуры НС. То есть, у всех особей будет одна и та же архитектура сети, но разные весовые коэффициенты. Этим они будут отличаться друг от друга. Соответственно, длина хромосомы будет определяться общим числом коэффициентов НС. Реализация нейронной сетиСледующим шагом нам нужно реализовать полносвязную НС с заданным числом входов, слоев и нейронов в каждом слое. Для этого, конечно, можно воспользоваться одним из стандартных пакетов по моделированию НС, например, Keras:
Но я сделаю проще – реализую сеть с помощью матриц пакета NumPy, чтобы вам не пришлось дополнительно устанавливать достаточно объемный пакет Keras только чтобы использовать достаточно простую НС. Реализацию нейронной сети сделаю в отдельном файле (модуле) с именем neuralnetwork.py. Вначале импортируем пакет NumPy: import numpy as np А, затем, объявим класс NNetwork. Я его приведу сразу целиком, так как он достаточно прост (также его можно будет скачать по ссылке с github): class NNetwork: """Многослойная полносвязная нейронная сеть прямого распространения""" @staticmethod def getTotalWeights(*layers): return sum([(layers[i]+1)*layers[i+1] for i in range(len(layers)-1)]) def __init__(self, inputs, *layers): self.layers = [] # список числа нейронов по слоям self.acts = [] # список функций активаций (по слоям) # формирование списка матриц весов для нейронов каждого слоя и списка функций активации self.n_layers = len(layers) for i in range(self.n_layers): self.acts.append(self.act_relu) if i == 0: self.layers.append(self.getInitialWeights(layers[0], inputs+1)) # +1 - это вход для bias else: self.layers.append(self.getInitialWeights(layers[i], layers[i-1]+1)) # +1 - это вход для bias self.acts[-1] = self.act_th #последний слой имеет пороговую функцию активакции def getInitialWeights(self, n, m): return np.random.triangular(-1, 0, 1, size=(n, m)) def act_relu(self, x): x[x < 0] = 0 return x def act_th(self, x): x[x > 0] = 1 x[x <= 0] = 0 return x def get_weights(self): return np.hstack([w.ravel() for w in self.layers]) def set_weights(self, weights): off = 0 for i, w in enumerate(self.layers): w_set = weights[off:off+w.size] off += w.size self.layers[i] = np.array(w_set).reshape(w.shape) def predict(self, inputs): f = inputs for i, w in enumerate(self.layers): f = np.append(f, 1.0) # добавляем значение входа для bias f = self.acts[i](w @ f) return f Я не стану сейчас пускаться во все тяжкие и погружаться в детали этого кода, если есть желание, то сделайте это самостоятельно, а ниже приведу список методов класса NNetwork:
Реализация генетического алгоритмаТеперь у нас все готово для создания генетического алгоритма. Вначале, как всегда, сделаем импорт необходимых зависимостей: import time from deap import base, algorithms from deap import creator from deap import tools import algelitism from neuralnetwork import NNetwork import random import matplotlib.pyplot as plt import numpy as np import gym Затем, создадим виртуальное окружение CartPole-v1, нейронную сеть и определим необходимые глобальные параметры: env = gym.make('CartPole-v1') NEURONS_IN_LAYERS = [4, 1] # распределение числа нейронов по слоям (первое значение - число входов) network = NNetwork(*NEURONS_IN_LAYERS) LENGTH_CHROM = NNetwork.getTotalWeights(*NEURONS_IN_LAYERS) # длина хромосомы, подлежащей оптимизации LOW = -1.0 UP = 1.0 ETA = 20 # константы генетического алгоритма POPULATION_SIZE = 20 # количество индивидуумов в популяции P_CROSSOVER = 0.9 # вероятность скрещивания P_MUTATION = 0.1 # вероятность мутации индивидуума MAX_GENERATIONS = 50 # максимальное количество поколений HALL_OF_FAME_SIZE = 2 hof = tools.HallOfFame(HALL_OF_FAME_SIZE) RANDOM_SEED = 42 random.seed(RANDOM_SEED) Далее, нам нужно создать класс для индивида. Так как генетический алгоритм должен максимизировать функцию приспособленности, то определим вспомогательный класс FitnessMax с весом 1.0: creator.create("FitnessMax", base.Fitness, weights=(1.0,)) creator.create("Individual", list, fitness=creator.FitnessMax) Следующими строчками зарегистрируем функции для генерации начальных значений в хромосомах индивидуумов, для создания индивидуума и всей популяции: toolbox = base.Toolbox() toolbox.register("randomWeight", random.uniform, -1.0, 1.0) toolbox.register("individualCreator", tools.initRepeat, creator.Individual, toolbox.randomWeight, LENGTH_CHROM) toolbox.register("populationCreator", tools.initRepeat, list, toolbox.individualCreator) population = toolbox.populationCreator(n=POPULATION_SIZE) Далее, нам нужно сформировать функцию для вычисления приспособленности каждой отдельной особи. Она будет выглядеть так: def getScore(individual): network.set_weights(individual) observation = env.reset() actionCounter = 0 totalReward = 0 done = False while not done: actionCounter += 1 action = int(network.predict(observation.reshape(1, -1))) observation, reward, done, info = env.step(action) totalReward += reward return totalReward, Вначале мы заносим в НС коэффициенты из хромосомы особи. Затем, инициализируем виртуальное окружение и запускаем цикл имитации внешней среды по шагам. На каждом шаге вычисляем управляющее воздействие с помощью НС и пока шест не упал, увеличиваем вознаграждение. Следующими строчками регистрируем функции для определения приспособленности, отбора особей, скрещивания и мутации: toolbox.register("evaluate", getScore) toolbox.register("select", tools.selTournament, tournsize=2) toolbox.register("mate", tools.cxSimulatedBinaryBounded, low=LOW, up=UP, eta=ETA) toolbox.register("mutate", tools.mutPolynomialBounded, low=LOW, up=UP, eta=ETA, indpb=1.0/LENGTH_CHROM) stats = tools.Statistics(lambda ind: ind.fitness.values) stats.register("max", np.max) stats.register("avg", np.mean) Здесь (кроме функции getScore) используются стандартные функции пакета DEAP, о которых мы с вами уже говорили на предыдущих занятиях. Наконец, запускаем ГА, собираем статистику и отображаем ее в виде графиков. population, logbook = algelitism.eaSimpleElitism(population, toolbox, cxpb=P_CROSSOVER, mutpb=P_MUTATION, ngen=MAX_GENERATIONS, halloffame=hof, stats=stats, verbose=True) maxFitnessValues, meanFitnessValues = logbook.select("max", "avg") best = hof.items[0] print(best) plt.plot(maxFitnessValues, color='red') plt.plot(meanFitnessValues, color='green') plt.xlabel('Поколение') plt.ylabel('Макс/средняя приспособленность') plt.title('Зависимость максимальной и средней приспособленности от поколения') plt.show() После закрытия окна с графиками запустим визуализацию виртуального окружения с лучшим индивидуумом: observation = env.reset() action = int(network.predict(observation.reshape(1, -1))) while True: env.render() observation, reward, done, info = env.step(action) if done: break time.sleep(0.03) action = int(network.predict(observation.reshape(1, -1))) env.close() Видим, как нейронная сеть умело управляется с тележкой, сохраняя шест в вертикальном положении. И вся эта «магия» была достигнута за счет использования ГА совместно с НС. Возможно, подобная «магия» создала и всех живых существ на нашей планете. По крайней мере, результат получился весьма впечатляющим. Видео по теме |