|
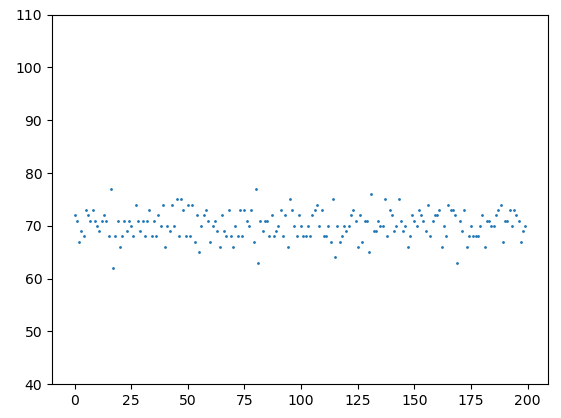
Как генетический алгоритм находит решенияАрхив проекта: ga_4.py На предыдущем занятии мы с вами реализовали простой ГА для решения задачи OneMax. Но за рамками остается вопрос, как же ему все же удается находить решение задачи? На этом занятии я попытаюсь ответить на него, для чего добавлю визуализацию приспособленностей особей на каждой итерации (поколении). Вначале у статистки зарегистрируем еще один параметр: stats.register("values", np.array) который будет хранить список значений функции приспособленности для каждого поколения, то есть, на выходе мы получим двумерный список values. Затем, прочитаем все сформированные данные: maxFitnessValues, meanFitnessValues, vals = logbook.select("max", "avg", "values") и анимируем изменение приспособленностей особей от поколения к поколению: import time plt.ion() fig, ax = plt.subplots() line, = ax.plot(vals[0], ' o', markersize=1) ax.set_ylim(40, 110) for v in vals: line.set_ydata(v) plt.draw() plt.gcf().canvas.flush_events() time.sleep(0.5) plt.ioff() plt.show() Если эти строчки программы вам не понятны, то подробнее о создании анимации в пакете matplotlib смотрите вот это занятие: После запуска программы увидим анимацию из множества точек:
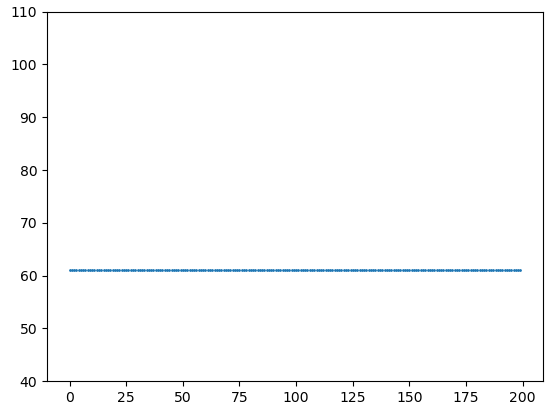
Каждая точка здесь – это значение функции приспособленности отдельного индивида в текущем поколении. От кадра к кадру происходит смена поколений и мы видим, что в целом, популяция стремится к уровню 100 – максимальному значению приспособленности. Так за счет чего происходит такое улучшение? Рассмотрим подробнее процесс эволюции, заложенный в ГА. Как считал Чарльз Дарвин, движущая сила эволюции – это естественный отбор. В нашем алгоритме за это отвечает функция select: toolbox.register("select", tools.selTournament, tournsize=3) А сам отбор происходит за счет турнира (состязания) трех случайно выбранных особей. Давайте посмотрим, что именно дает только одна эта функция. Отключим кроссинговер и мутации (поставим вероятности их возникновения, равные нулю): population, logbook = algorithms.eaSimple(population, toolbox, cxpb=0, #P_CROSSOVER, mutpb=0, #P_MUTATION, ngen=MAX_GENERATIONS, stats=stats, verbose=False) И после нескольких итераций, все особи окажутся одинаковыми, равные лучшему индивидууму в начальной популяции:
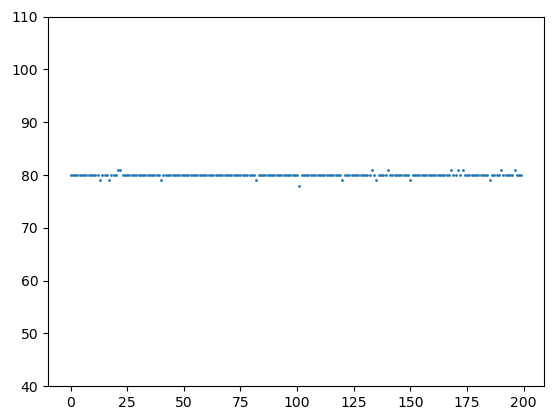
Но дальше процесс не пошел, популяция не стала улучшаться и достигать максимально возможного уровня в 100 единиц. И это очевидно, так как хромосомы в начальной популяции никак не меняются, здесь только отбрасываются худшие и не более того. В результате, разнообразие особей утрачивается и все становятся идентичны друг другу. Также очевидно, что мы можем добавлять разнообразие в хромосомы с помощью мутации генов. Для этого вернем значение параметра: mutpb=P_MUTATION, Действительно, это вносит разнообразие в популяцию, время от времени появляются лучшие особи и оператор отбора, затем, подгоняет остальных особей вверх, делая популяцию лучше. Однако, после 50 итераций (поколений) лучшего решения в 100 единиц так и не было достигнуто:
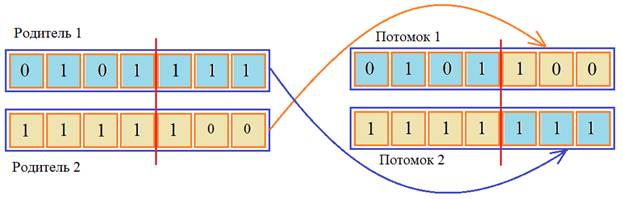
Даже, если увеличить вероятность мутации, все равно скорость сходимости алгоритма к оптимальному решению оказывается ниже, чем с операцией кроссинговера (скрещивания). Этот пример хорошо показывает, что генетический алгоритм – это не просто направленный случайный поиск, когда мы случайным образом меняем значение параметра, а затем, смотрим близость к решению. Здесь важную роль играет оператор кроссинговера (скрещивания), когда части хромосом родителей перемешиваются для получения потомков:
И это работает гораздо эффективнее простой мутации. Представьте, что в двух разных частях хромосом родителей уже сформировано оптимальное решение. Тогда достаточно произвести обмен и будет получен потомок с наилучшим набором генов. Именно благодаря этому операция кроссинговера дает заметное ускорение сходимости ГА к оптимальному решению. Давайте снова включим его и убедимся в этом: cxpb=P_CROSSOVER, Может быть, тогда мутация не играет особой роли и ее можно отключить и ГА с тем же успехом будет находить наилучшее решение? Давайте проверим. Поставим вероятность мутации ноль: mutpb=0, и после запуска программы увидим следующий результат:
Видите, в процессе скрещивания и отбора были потеряны особи, которые хранили нужные гены для достижения оптимального решения. Мутация решает эту проблему. Она постоянно вносит небольшое разнообразие в популяцию и случайно потерянная информация (фрагменты хромосом) также случайно восстанавливается. Это гарантирует, при большом числе итераций, существование достаточных данных для нахождения оптимального решения. Преимущества и недостатки ГАКак у всех алгоритм, ГА имеют свои преимущества и недостатки по сравнению с другими алгоритмами оптимизации (назовем их классическими). Начнем с преимуществ:
Недостатки генетических алгоритмовК общим недостаткам при реализации ГА можно отнести следующие моменты:
Видео по теме |