|
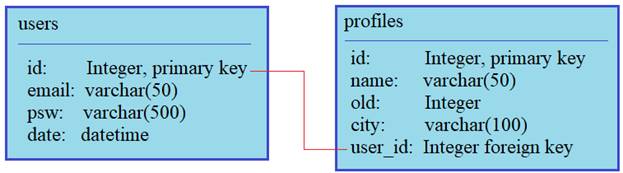
Операции с таблицами через Flask-SQLAlchemyФайл проекта: https://github.com/selfedu-rus/flsite_sqlalchemy-23 На предыдущем занятии мы с вами создали две таблицы, используя механизм SQLAlchemy, и объявили функцию-представления для регистрации новых пользователей. И теперь пришло время разобраться с чтением данных из таблиц. Выборка записей из таблицКак вы помните, у нас в БД две таблицы, причем, они связаны между собой через внешний ключ user_id таблицы profiles:
Наша задача сделать выборку по пользователям, в которой бы фигурировали данные из обеих таблиц. Но для начала посмотрим, как вообще осуществляется получение данных. Для демонстрации я перейду в консоль Python и выполню команду: from app import db, Users, Profiles то есть, из нашего текущего модуля app импортируем переменную db и классы Users, Profiles. Далее, чтобы выбрать все записи, например, из таблицы users, следует выполнить метод all объекта query: Users.query.all() и на выходе получим список объектов, которые отображаются в соответствии с определением магического метода __repr__ в классе Users: [<users 1>, <users 2>, <users 3>] Здесь объект query берется из базового класса db.Model, от которого образованы классы Users и Profiles. Благодаря концепции наследования в ООП, мы автоматически получаем полный функционал для работы с таблицами БД. Давайте теперь сохраним возвращаемый список в переменной res: res = Users.query.all() и посмотрим на ее содержимое. Мы видим, что это коллекция объектов и каждый объект содержит атрибуты: id, email, psw, date. Как раз те, что мы определяли в классе Users и те, что были прочитаны из соответствующей таблицы БД. То есть, мы можем обратиться к любому элементу и вывести нужное нам свойство, например, так: res[0].email Получим email из первой записи. По аналогии работает метод first, только он возвращает первую запись, соответствующего запроса (или значение None, если ничего нет): f = Users.query.first() f.id Далее, для выбора записей по определенному критерию можно воспользоваться методы filter_by и filter: Users.query.filter_by(id = 1).all() Users.query.filter(Users.id == 1).all() Разница между этими методами в том, что в filter_by передаются именованные параметры, а в filter прописывается логическое выражение. Поэтому последний метод обладает большей гибкостью, например, можно вывести все записи с id>1: Users.query.filter(Users.id > 1).all() Также можно делать ограничение на максимальное число возвращаемых записей: Users.query.limit(2).all() Выполнять сортировку по определенному полю: Users.query.order_by(Users.email).all() Users.query.order_by(Users.email.desc()).all() Или, просто получать пользователя по значению первичного ключа: Users.query.get(2) Разумеется, все эти методы можно комбинировать и создавать более сложные запросы. Выборка из нескольких таблицНу хорошо, мы увидели как можно выбирать записи из одной конкретной таблицы. Но как объединить данные, например, из двух наших таблиц и сформировать одну общую выборку? Для этого нужно соединить записи таблиц по внешнему ключу user_id, следующим образом: res = db.session.query(Users, Profiles).join(Profiles, Users.id == Profiles.user_id).all() Здесь вначале в методе query указываются таблицы, формирующие выборку. Затем, используется метод join, в котором прописывается условие связывания записей этих двух таблиц. И в конце, метод all возвращает все записи, удовлетворяющие запросу. На выходе переменная res будет ссылаться на список, содержащий выбранные данные. К ним можно обратиться, используя следующую конструкцию: res[0].Users.email или res[0].Profiles.name Однако, SQLAlchemy предоставляет нам еще один довольно удобный механизм связывания таблиц. Если мы наперед знаем, что необходимо выбирать для каждого пользователя информацию из таблиц users и profiles, то в классе Users, как таблицы с «первичными данными», к которой подбираются соответствующие записи из «вторичной таблицы» profiles, можно прописать специальную переменную: pr = db.relationship('Profiles', backref='users', uselist=False) Через эту переменную будет устанавливаться связь с таблицей Profiles по внешнему ключу user_id. Параметр backref указывает таблицу, к которой присоединять записи из таблицы profiles. Последнее значение uselist=False указывает, что одной записи из users должна соответствовать одна запись из profiles, что, в общем-то, и должно быть. Теперь, выполняя простую команду: res = Users.query.all() в объектах списка будет присутствовать атрибут pr, который ссылается на объект Profiles с соответствующими данными: res[0].pr res[0].pr.name Как видите, все довольно удобно. Мы воспользуемся этим механизмом и отобразим на главной странице сайта список зарегистрированных пользователей: @app.route("/") def index(): info = [] try: info = Users.query.all() except: print("Ошибка чтения из БД") return render_template("index.html", title="Главная", list=info) И модифицируем шаблон: {% extends 'layout.html' %} {% block content %} <ul> {% for u in list %} <li>id: {{u.id}}, email: {{u.email}}</p> <ul> <li>Имя: {{u.pr.name}}</li> <li>Возраст: {{u.pr.old}}</li> <li>Город: {{u.pr.city}}</li> </ul> </li> {% endfor %} </ul> {% endblock %} Все, теперь на главной странице видим информацию о пользователях из обеих таблиц. ЗаключениеНа этом мы завершим серию занятий по микрофреймворку Flask. Конечно, коснуться всех деталей в рамках видеоуроков просто нереально. В частности, модуль SQLAlchemy нами был рассмотрен лишь обзорно, чтобы дать основные представления об этом весьма полезном расширении, которое повсеместно используется при работе с БД. И, если вы задумали создать сайт на Flask, то обязательно используйте его (или какой-либо подобный) для работы с таблицами БД. Это избавит вас в будущем от большого количества проблем, и, кроме того, при трудоустройстве по этому профилю знание SQLAlchemy будет весьма кстати. Хорошей отправной точкой в его изучении будет страница документации на русском языке: https://flask-sqlalchemy-russian.readthedocs.io/ru/latest/index.html Видео по теме |