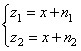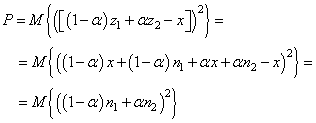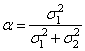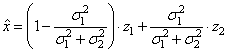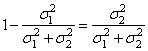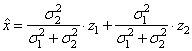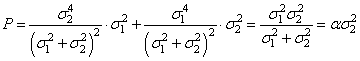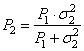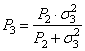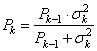|
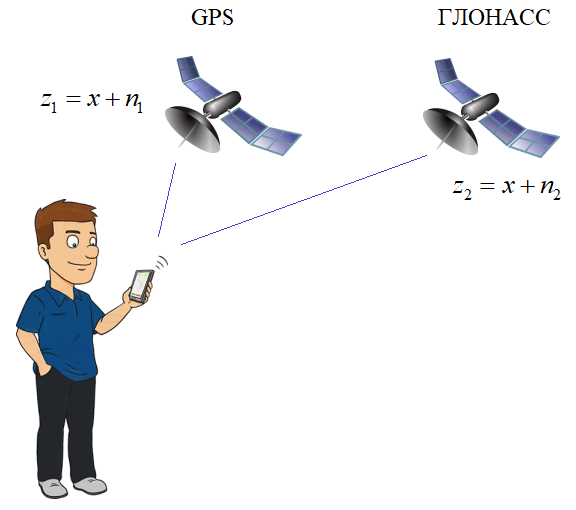
Фильтр Калмана дискретного времениНа этом занятии рассмотрим принцип работы одного, довольно популярного фильтра, который известен под названием «фильтр Кламана». Чтобы лучше понять этот материал, я решил рассмотреть его с позиций конкретного примера. Предположим, что производятся наблюдения текущего местоположения координаты x стоящего на одном месте человека, используя два источника информации: ГЛОНАСС и GPS:
В определенный момент времени на входе устройства фиксируются наблюдения от этих систем навигации:
Причем, текущее
значение полезного сигнала (координата x) искажаются
аддитивными шумами:
Здесь
Это примерные значения, используемые исключительно для этого занятия. Настоящие нужно смотреть по документации этих систем или из результатов предварительных экспериментов. Итак, мы имеем два
наблюдения
Здесь возникает две задачи: во-первых, как построить этот алгоритм и, во-вторых, как оценить качество работы этого алгоритма. Начнем со второй задачи, так как именно от критерия качества зависит вид алгоритма. Очевидно, что любой алгоритм будет приводить к ошибкам оценивания:
При наилучшем алгоритме эти ошибки от эксперимента к эксперименту будут, в среднем, колебаться вокруг нулевого значения, то есть, иметь нулевое МО:
И, понятно, что чем меньше ошибка, тем лучше. Но ее саму неудобно брать как критерий качества, т.к. может принимать и положительные и отрицательные значения, а нам бы хотелось сформировать критерий, который бы говорил: чем он больше, тем хуже работает алгоритм, чем меньше – тем лучше. Поэтому, в данном случае хорошо подходит квадрат ошибки и тогда критерий становится таким:
Но и здесь есть подводный камень: при одном эксперименте эта величина может быть небольшой, а при другом – намного больше. Поэтому логичнее было бы построить алгоритм, который бы минимизировал не конкретный квадрат ошибки, а в среднем давал бы как можно меньшие ошибки. Понятие в среднем – это, фактически, математическое ожидание, то есть, окончательно, наш критерий качества принимает вид:
Таким образом, нам нужно минимизировать дисперсию (разброс) ошибок оценивания. Отлично, с этим разобрались. Как нам теперь построить алгоритм, который бы минимизировал этот критерий? Было доказано, что в случае гауссовских шумов минимум дисперсии ошибки обеспечивает следующий алгоритм:
где
Однако, здесь задачу поиска двух коэффициентов можно свести к нахождению всего одного, если заметить, что:
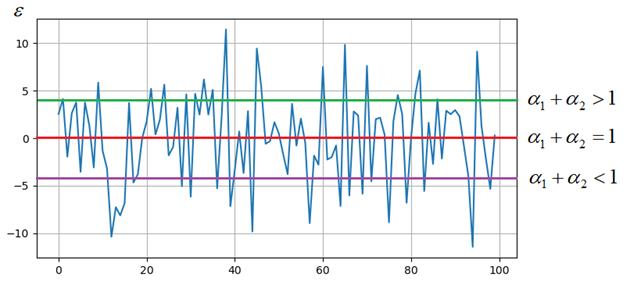
Почему это так? Когда мы с вами определяли величину ошибки:
то говорили, что хороший алгоритм делает ее среднее равное нулю. Так вот, если сумма коэффициентов будет больше 1, то, в среднем, будут получаться значения выше нулевого уровня. При сумме меньше 1 – ниже нулевого уровня и только при сумме равной 1 получим нулевое среднее ошибок, то есть, оценка на выходе алгоритма будет несмещенной.
В результате, наш алгоритм обработки наблюдений, принимает вид:
и критерий качества:
Распишем выражение под МО, учитывая, что
получим:
Учитывая независимость наблюдений и шумов, квадрат суммы распадается на сумму квадратов:
В итоге, мы выразили критерий качества непосредственно через дисперсии шумов наблюдений от каждого из источников. Этот критерий в зависимости от параметра α образует параболу с единственной точкой минимума. Из школьного курса математики мы знаем, что для нахождения точки минимума, нужно вычислить производную по параметру альфа и приравнять ее нулю:
откуда
Мы нашли оптимальное значение весового коэффициента, который будет минимизировать квадрат средних ошибок оценивания, а сам алгоритм обработки принимает вид:
или, учитывая, что
приходим к виду:
Что, фактически, означает эта формула? В действительности, мы здесь как бы взвешиваем два наблюдения и большее значение (вес) отдается тому, которое имеет меньшую дисперсию шума. Например, для значений
вес первого наблюдения будет выше второго. И это логично, т.к. первое наблюдение содержит, в среднем, более точную информацию о параметре x, чем второе. А вот если бы их дисперсии были одинаковыми, то оценка строилась бы как среднее арифметическое от наблюдений:
Полученный алгоритм оценивания можно воспринимать как частный случай реализации фильтра Калмана. И, в целом, отражает суть его работы: взвешивание двух наблюдений для формирования выходной оценки параметра. Для оценки качества работы этого алгоритма, мы можем в формулу дисперсии ошибки оценивания:
подставить вычисленные
значения для
Причем, отсюда видно, что оптимальное значение параметра α также равно отношению дисперсии ошибки оценивания на дисперсию шума второго наблюдения:
Сделаем последний шаг и приведем форму записи фильтра Калмана к рекуррентному виду. Смотрите, вот эту формулу:
можно представить и в таком виде:
или, подставляя вместо α выражение через дисперсию ошибок оценивания:
Именно в таком виде принято записывать фильтр Калмана в научной литературе. Эта формула, фактически, означает, что если наблюдения поступают на вход приемника последовательно друг за другом с определенным интервалом времени, то оценка по первому наблюдению, это просто:
с ошибкой оценивания
Когда приходит
второе, с дисперсией шума
а, затем, уточняется оценка:
Получаем алгоритм рекуррентного построения оценок. Далее, когда придет еще одно наблюдение, допустим от GPS в следующий момент времени:
с дисперсией
шума
и пересчитываем оценку:
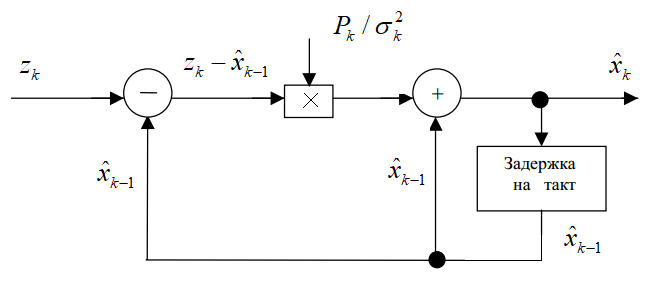
И так далее. Достоинством фильтра Калмана является возможность именно рекуррентного вычисления оптимальных оценок по наблюдениям, непрерывно поступающих на вход некоторого устройства. То есть, для любого k-го наблюдения, получим алгоритм пересчета:
и
Вот это выражение и представляет собой фильтр Калмана в дискретном времени.
То есть, по мере
увеличения числа наблюдений мы будем получать все более точную оценку
Причем, благодаря рекуррентному принципу работы фильтра, его вычислительная сложность остается постоянной при любом числе наблюдений – это его ключевая особенность. Видео по теме |