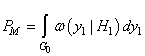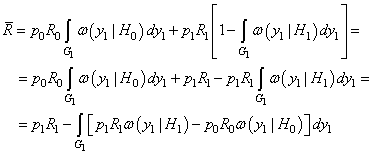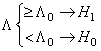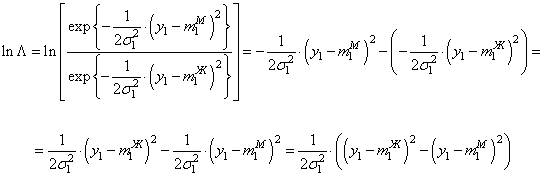|
Байесовский классификатор, отношение правдоподобияРеализация алгоритма на Python (lesson 10. Recognize.py) На этом занятии мы с вами рассмотрим известный и часто цитируемый в литературе алгоритм, различения сигналов на основе критерия Байеса. Предположим, что у нас имеются наблюдения роста и веса человека:
И по значениям этих наблюдений нужно сделать вывод: мужчина это или женщина. То есть, мы рассматриваем объект человек и этот объект может находиться в двух состояниях:
с известными
априорными вероятностями:
Имея конкретные
значения наблюдений
Соответственно, здесь возможны как верные результаты, так и ошибки. Это удобно представить в виде следующей таблицы:
Здесь величина
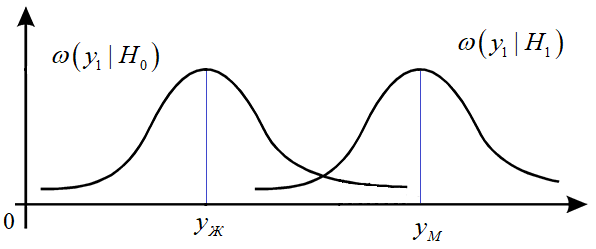
(вероятность) ошибки Например, если отдельно рассмотреть распределение веса мужчин и женщин, то их примерно можно представить следующими условными гауссовскими ПРВ:
Здесь
То есть, мы
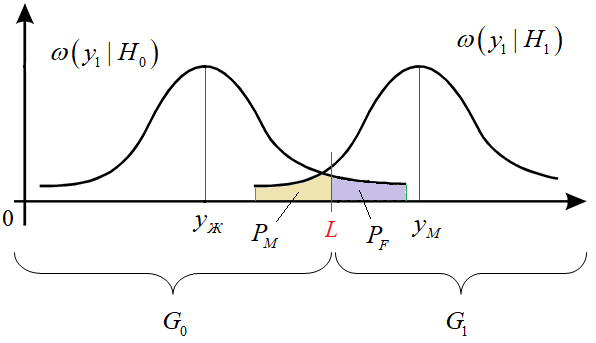
имеем две непересекающиеся области значений:
иначе,
выдвигается гипотеза
Следовательно, вероятность 1-го рода, равна:
а вероятность 2-го рода:
Чтобы у нас
интегрирования выполнялось в пределах одной области, например,
И далее, выбирать порог L так, чтобы минимизировать вероятности ошибок. Как вы понимаете, уменьшая одну, увеличиваем другую. Поэтому «разумный» критерий оптимального выбора должен быть построен на основе компромисса между вкладом двух типов возможных ошибок. Так вот, при байесовском подходе к задаче обнаружения каждой ошибке назначают определенный размер штрафа:
то есть, это
числа и чем больше одно число по отношению ко второму, тем больший штраф
назначается соответствующей ошибке. Например, если мы хотим меньше ошибаться
при определении женщин по весу, то есть, иметь меньше ошибок
Если же нам в равной степени важны определение и мужчин и женщин, то штрафы следует выбирать равными:
Затем, используя эти величины, байесовский критерий качества формулируется как минимум средних ошибок:
Распишем формально этот критерий, получим:
Подставляя
вместо
Та же картина будет наблюдаться, если мы обобщим этот результат на многомерный случай, то есть, будем использовать вектор наблюдений:
Очевидно, средние потери будут минимальны, если интеграл
будет
максимален. Фактически, он определяет конфигурацию и правило выбора области
то такой вектор
следует отнести к области Давайте перепишем это неравенство в более удобном виде:
Здесь справа записано число, а слева – отношение ПРВ. Данное неравенство получило название отношение правдоподобия и определяет оптимальное с точки зрения минимума средних байесовских потерь классификацию объектов. Часто его еще записывают в таких обозначениях:
и правило классификации принимает вид:
Давайте применим это правило к решению нашей задачи классификации мужчин и женщин на основе веса (чтобы не усложнять восприятие информации):
где
а априорные вероятности, как в начале нашего занятия:
Теперь у нас есть все для реализации алгоритма классификации. Только мы вместо изначального отношения правдоподобия возьмем натуральные логарифмы от величин:
Это упростит решение задачи и при этом не исказит работу алгоритма, т.к. неравенство при любой монотонной функции остается неизменным. Итак, вычислим натуральный логарифм от отношения двух условных ПРВ, получим:
Выглядит громоздко, но в действительности, здесь простая школьная математика. Далее, все это сравнивается с порогом:
Реализация на PythonРеализуем это на Python, программа будет следующей: import numpy as np def getL(y1, m1_F, m1_M, d1): res = 1/(2*d1)*((y1-m1_F)**2 - (y1-m1_M)**2) return res def getL0(p0, p1): return np.log(p0/p1) m1_F = 60 # средний вес женщин (кг) m1_M = 85 # средний вес мужчин (кг) d1 = 9 # дисперсия разброса веса (кг^2) p0 = 0.48 # вероятность для женщин p1 = 0.52 # вероятность для мужчин N = 100 # число экспериментов L0 = getL0(p0, p1) nM = 0 for i in range(N): y1 = np.random.normal(m1_F, d1) L = getL(y1, m1_F, m1_M, d1) if(L >= L0): print("Мужчина", y1) nM += 1 else: print("Женщина", y1) error = nM/N*100 print(f"Ошибка: {np.round(error, 2)}%") Видео по теме |