|
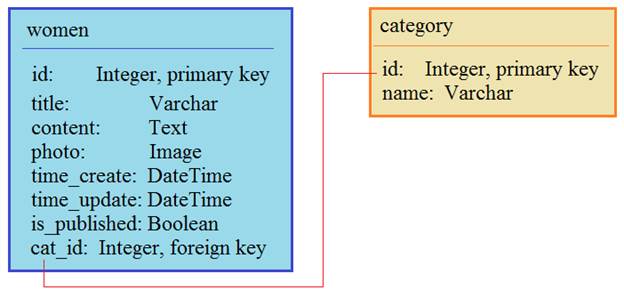
Основы ORM Django за часКурс по Django: https://stepik.org/a/183363?utm_source=proproprogs Архив проекта: lesson-16-coolsite.zip На этом занятии мы рассмотрим основные команды ORM Django (иногда еще говорят API модели). Это будет лишь обзорное занятие огромной темы. Если вы уже знакомы с ORM, то можно пропустить его и переходить к следующим темам. Для всех остальных – это введение, чтобы у вас сформировалось начальное представление об использовании этого API. Некоторое введение у нас уже было, когда мы рассматривали операции для одной конкретной модели (таблицы). Здесь же углубимся в эту тему и посмотрим, как можно выполнять манипуляции со связанными таблицами. В качестве примера у нас будет две наших ранее созданных модели: Women и Category, которые связаны по внешнему ключу:
Вообще, ORM Django имеет очень богатый функционал и вам вряд ли понадобится переходить на уровень SQL-запросов, все можно сделать на уровне этого API. Кроме того, начинающим разработчикам уровень ORM позволит писать грамотные и оптимизированные запросы к БД любого типа: SQLite, MySQL, PostgreSQL, Oracle, то есть, приложение будет совершенно независимым от типа СУБД. Все это и привело к тому, что сейчас, в основном, используются различные ORM при работе с таблицами БД. Подробную информацию обо всем этом можно посмотреть на сайте русскоязычной документации: в разделе «ORM и работа с базой данных» и подразделе «QuerySet». В частности ссылка «методы QuerySet»: https://djbook.ru/rel3.0/ref/models/querysets.html приводит нас на страницу с описанием различных методов, которые доступны в ORM Django. Как всегда, советую с ними подробно ознакомиться, чтобы грамотно их использовать в своих проектах. Чаще всего используются методы: filter, all, get, о которых мы уже немного говорили. Также здесь вы найдете, так называемые, lookup’ы, которые позволяют формировать различные условия для выборки записей, и ниже представлены функции агрегации. Чтобы демонстрировать работу команд, я перейду в терминал и запущу оболочку Django: python manage.py shell Первой строчкой импортирую модели, с которыми будем работать: from women.models import * Давайте проверим, все ли работает корректно. Выполним уже знакомую нам команду для выборки всех записей из таблицы women: Women.objects.all() Мы видим список, порядок сортировки которого определен в классе Meta класса модели Women. Если нужно отобрать не все записи, а лишь некоторые из них, то можно использовать синтаксис срезов, чтобы Django указать сделать это, например, так: Women.objects.all()[:5] Получим первые пять записей. Вы можете подумать, что здесь просто берется срез из полученного списка записей на уровне языка Python. Но это не так. В действительности, отбор происходит на уровне SQL-запроса. И если выполнить команду: from django.db import connection connection.queries то в конце последнего запроса увидим фрагмент «LIMIT 5». А при выполнении такой команды: Women.objects.all()[3:8] получим в запросе «LIMIT 5 OFFSET 3». То есть, здесь везде делается отбор на уровне SQL-запросов, что очень эффективно. Далее, если нужно поменять порядок и отсортировать записи по определенному полю, то используется метод order_by(): Women.objects.order_by('pk') В данном случае мы сортируем записи по их идентификатору. Почему здесь используется имя поля pk, а не id? Как я уже отмечал, по соглашению в Django имя pk по умолчанию используется для обращения к первичному ключу, так как это поле в таблице мы могли бы назвать не id, а как то иначе. Чтобы сделать его название универсальным на уровне ORM, Django и использует это имя pk. Сразу же здесь напомню, что символ минус перед именем поля означает обратный порядок сортировки: Women.objects.order_by('-pk') Также порядок (на противоположный) можно менять с помощью метода reverse(): Women.objects.all().reverse() Он удобен, если формируется некая выборка и нам нужно просто поменять порядок следования записей на противоположный. Здесь уже нет необходимости указывать конкретное поле, а просто записать reverse(). На одном из прошлых занятий я вам приводил пример метода filter() для выбора нескольких записей по некоторому условию: Women.objects.filter(pk__lte=2) и метод get() для получения строго одной записи: Women.objects.get(pk=2) Но не сказал, что filter() всегда возвращает записи в виде списка, а get() – в виде одного объекта (экземпляра модели). Обычно, метод get() необходим для выбора строго одной записи и для этого использую или поле pk, или поле slug (они оба создаются как уникальные). Давайте теперь посмотрим, как происходит обработка связанных данных. Сохраним объект какой-либо записи в переменной w: w = Women.objects.get(pk=1) и здесь нам доступны следующие свойства:
Опять же, на одном из прошлых занятий, посвященном связанным моделям, я объяснял отличия между классом модели и его экземплярами. Здесь я не буду повторяться, если есть необходимость, то посмотрите его. Давайте, для примера, выполним строчку, чтобы убедиться, что cat – это действительно ссылка на экземпляр класса Category: w.catСоответственно, для получения связанных данных о категории, можно использовать этот объект, например, так: w.cat.name получим название категории. Причем, получение конкретных связанных данных происходит только в момент обращения к ним. В данном случае в строчке w.cat Django автоматически сгенерировал запрос к таблице category и взял запись с id = cat_id. Таким образом, мы увидели как вторичная модель Women связывается с первичной моделью Category и получает соответствующие данные. Но можно сделать и наоборот, используя первичную модель Category получить все связанные с ней посты из вторичной модели Women. Для этого у любой первичной модели по умолчанию автоматически создается специальное свойство (объект) с именем: <вторичная модель>_set И уже с его помощью можно выбирать связанные записи. Давайте сделаем это. Сначала прочитаем запись из таблицы category, например, с id=1: c = Category.objects.get(pk=1) чтобы получить ссылку на объект записи первичной модели. А, затем, используя механизм обратного связывания, прочитаем все связанные с данной категорией посты: c.women_set.all() Если мы хотим переименовать атрибут women_set, то для этого в классе ForeignKey вторичной модели Women следует дополнительно прописать параметр: related_name='get_posts' Здесь get_posts – это новое имя атрибута для обратного связывания. Чтобы изменения вступили в силу, нужно выйти из оболочки Django, снова зайти, импортировать модели, прочитать категорию и отобразить связанные посты с уже новым именем атрибута: from women.models import * c = Category.objects.get(pk=2) c.get_posts.all() Разумеется, вместо метода all() мы можем использовать и другие уже известные нам методы, например, filter(): c.get_posts.filter(is_published=True) (Убираем параметр related_name и перезапускаем оболочку). Фильтры полейПри выборке записей, например, с помощью функции filter() можно использовать расширения имен атрибутов модели. Это, так называемые, lookups. С двумя из них мы ранее уже познакомились:
Но есть и другие. Полный их список можно посмотреть по ссылке (в разделе Field lookups): https://djbook.ru/rel3.0/ref/models/querysets.html Давайте воспользуемся фильтром gt (больше, чем) для выборки записей с идентификатором больше 2. Это делается так: Women.objects.filter(pk__gt=2) На уровне SQL-запроса увидим фрагмент «WHERE id > 2», который соответствует этому фильтру: from django.db import connection connection.queries Рассмотрим еще несколько интересных примеров lookups. Фильтр contains позволяет находить строки по их фрагменту, учитывая регистр букв. Например, вот такая команда: Women.objects.filter(title__contains='ли') выдаст список всех женщин, в заголовке у которых присутствует фрагмент «ли». Опять же, на уровне SQL-запроса это делается с помощью фрагмента: «WHERE title LIKE '%ли%'» Похожий фильтр icontains осуществляет поиск без учета регистра символов. Однако, если мы запишем вот такую команду: Women.objects.filter(title__icontains='ЛИ') то получим пустой список. Почему? Дело в том, что СУБД SQLite не поддерживает регистронезависимый поиск для русских символов (вообще, для всех не ASCII-символов), поэтому получаем пустой список. Другие СУБД, как правило, отрабатывают все это корректно. В случае с латинскими символами в SQLite поиск всегда проходит как регистронезависимый. Следующий полезный фильтр in позволяет указывать через список выбираемые записи по значениям. Например, выберем записи с id равными 2, 5, 11, 12: Women.objects.filter(pk__in=[2,5,11,12]) Если по условию нужно отработать сразу несколько фильтров, то они указываются через запятую: Women.objects.filter(pk__in=[2,5,11,12], is_published=True) Теперь мы видим всего две записи, так как посты с id 11 и 12 отмечены как неопубликованные. Причем, обратите внимание, указывая два критерия через запятую, на уровне SQL-запросов формируется связка через AND (логическое И): WHERE ("women_women"."is_published" AND "women_women"."id" IN (2, 5, 11, 12)) то есть, запись выбирается, если оба критерия срабатывают одновременно. Чтобы определять условия через OR (логическое ИЛИ) используется специальный класс Q. Речь о нем пойдет дальше. Также мы можем использовать фильтр in и для внешнего ключа, причем, записать его в двух видах: Women.objects.filter(cat__in=[1, 2]) Women.objects.filter(cat_id__in=[1, 2]) Результат будет один и тот же. Или, вместо указания конкретных id записей категорий, можно вначале прочитать нужные рубрики, например, все: cats = Category.objects.all() а, затем, подставить их вместо списка: Women.objects.filter(cat__in=cats) По аналогии используются и все остальные фильтры фреймворка Django. Использование класса QЕсли в условии нужно использовать логическое ИЛИ, а также НЕ, то вместо перечисления критериев отбора через запятую, следует использовать специальный класс Q. С помощью этого класса можно описывать более сложные критерии (условия), используя специальные операторы:
Давайте посмотрим, как это все работает. Вначале его нужно импортировать: from django.db.models import Q Теперь, смотрите, если выполнить вот такой запрос: Women.objects.filter(pk__lt=5, cat_id=2) то на выходе получим пустой список, т.к. все записи с id<5 относятся к первой категории. Но сейчас мы с помощью класса Q соединим эти два условия по логическому ИЛИ: Women.objects.filter(Q(pk__lt=5) | Q(cat_id=2)) И теперь видим записи, у который или id<5 или cat_id=2. Кстати, предыдущий запрос тоже можно записать через класс Q и он будет выглядеть так: Women.objects.filter(Q(pk__lt=5) & Q(cat_id=2)) Ну и, наконец, если перед классом прописать тильду, то условие превратится в обратное: Women.objects.filter(~Q(pk__lt=5) | Q(cat_id=2)) Здесь мы отбираем записи, у которых id >=5 или cat_id=2. Вот так можно использовать класс Q для описания запросов с использованием операторов &, | и ~. И всегда помните о приоритетах операций: сначала выполняется НЕ, затем, И и в последнюю очередь ИЛИ. Методы выбора записейВ ORM Django есть несколько полезных методов для быстрого получения определенных записей из таблицы. Например, чтобы взять первую запись из выборки, используется метод first(): Women.objects.first() Мы в этом можем убедиться, если выведем все посты: Women.objects.all() То есть, берется первая запись в соответствии с порядком сортировки модели. Мы можем поменять этот порядок и с помощью этого же метода first() выбирать разные записи, например, так: Women.objects.order_by('pk').first() Women.objects.order_by('-pk').first() Или же воспользоваться методом last() для выбора последней записи из набора: Women.objects.order_by('pk').last() Women.objects.filter(pk__gt=5).last() Методы latest и earliestЕсли в таблице присутствуют поля с указанием даты и времени, то для таких записей и таких таблиц можно применять методы:
Например: Women.objects.earliest('time_update') Women.objects.latest('time_update') Для чего могут понадобиться такие методы? Например, сделана выборка с сортировкой по какому-либо другому полю (не time_update) и из этой выборки нужно получить самую раннюю или самую позднюю запись: Women.objects.order_by('title').earliest('time_update') Методы get_previous_by_, get_next_by_Если нужно выбрать предыдущую или следующую запись относительно текущей, то в ORM для этого существует два специальных метода, которые выбирают записи опять же по указанному полю с датой и временем. Например, мы выбираем некую запись с pk=7: w = Women.objects.get(pk=7) Тогда, для получения предыдущей записи относительно текущей, можно записать: w.get_previous_by_time_update() Здесь суффикс time_update – это название поля, по которому определяется предыдущая запись. То есть, здесь используется не порядок следования записей в выборке, а временное поле. И уже по нему смотрится предыдущая или следующая запись: w.get_next_by_time_update() Дополнительно в этих методах можно указывать условия выборки следующей или предыдущей записи. Например: w.get_next_by_time_update(pk__gt=10) выбирается следующая запись с id больше 10. Методы exists и countВ ORM Django имеются два весьма полезных метода с высокой скоростью исполнения:
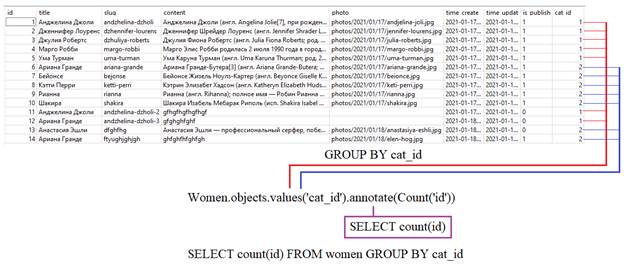
Они часто используются для реализации простых проверок до выполнения других, более сложных запросов. Давайте я добавлю в таблицу Category еще одну рубрику «Спортсменки» и эта рубрика пока у нас пуста, то есть, нет ни одной записи с ней связанной. Как вы уже догадались, мы сейчас протестируем метод exists(), который возвращает True, если записи есть и False – в противном случае. c3 = Category.objects.get(pk=3) c3.women_set.exists() Увидим False, а для второй категории: c2 = Category.objects.get(pk=2) c2.women_set.exists() получим значение True. Соответственно, вызывая второй метод, можем получить число записей: c2.women_set.count() или так: Women.objects.filter(pk__gt=4).count() То есть, методы exists() и count() применяются к любой выборке. Выборка записей по полям связанных моделейВ одном из прошлых занятий мы с вами выбирали все записи из модели Women для определенной категории, используя слаг: Women.objects.filter(cat__slug='aktrisy') Как это работает? В действительности, вот этот параметр cat__slug сформирован по следующему правилу: <имя первичной модели>__<название поля первичной модели> То есть, здесь мы обращаемся к первичной модели через атрибут cat, который прописан во вторичной модели Women, а затем, через два подчеркивания указываем имя поля тоже первичной модели, по которому отбираются записи уже вторичной модели. И на выходе получаем список постов для актрис. Этот синтаксис немного похож на использование фильтра in: Women.objects.filter(cat__in=[1]) Только здесь вместо указания списка идентификаторов рубрик, используется слаг с определенным названием. Во всем остальном принцип работы идентичен. Или, можно взять другое поле (name) и по нему произвести выборку записей из вторичной модели: Women.objects.filter(cat__name='Певицы') Мало того, после имени поля можно дополнительно указывать различные фильтры. Например, выберем записи, у которых имя категории содержит букву ‘ы’: Women.objects.filter(cat__name__contains='ы') Конечно, это несколько странный, искусственный пример, но он хорошо показывает принцип использования фильтров для полей первичной модели. Если уточнить этот фильтр: Women.objects.filter(cat__name__contains='цы') то получим уже записи только по певицам. Или сделать наоборот, выбрать все категории, которые связаны с записями вторичной модели Women, содержащие в заголовке фрагмент строки «ли»: Category.objects.filter(women__title__contains='ли') Обратите внимание, на выходе получим набор из нескольких повторяющихся категорий, каждая из которых соответствует определенной записи из модели Women. Если нужно отобрать только уникальные записи (категории), то дополнительно следует указать метод distinct(): Category.objects.filter(women__title__contains='ли').distinct() Агрегирующие функцииДалее, мы с вами рассмотрим несколько агрегирующих методов. С одним из них, мы в принципе, уже знакомы – это метод count(), который подсчитывает число записей. В самом простом случае, с его помощью можно определить число записей в таблице women: Women.objects.count() Подробно о том, что такое агрегация на уровне SQL-запросов, я уже рассказывал на занятии по SQLite и, если вы мало знакомы с этой информацией, то дополнительно советую посмотреть и это видео: https://www.youtube.com/watch?v=KXdiuTOEFGA Остальные агрегирующие команды обычно прописываются в специальном методе aggregate(), например: Women.objects.aggregate(Min('cat_id')) Но, чтобы ими воспользоваться, нужно их импортировать: from django.db.models import * и после этого предыдущая команда выдаст наименьшее значение для поля cat_id. Также можно прописывать сразу несколько команд: Women.objects.aggregate(Min('cat_id'), Max('cat_id')) На выходе получим следующий словарь: {'cat_id__min': 1, 'cat_id__max': 2} Если по каким-либо причинам стандартные ключи нам не подходят, и мы бы хотели их поменять, то делается это так: Women.objects.aggregate(cat_min=Min('cat_id'), cat_max=Max('cat_id')) С агрегирующими значениями можно выполнять различные математические операции, например: Women.objects.aggregate(res=Sum('cat_id') - Count('cat_id')) По аналогии используются все остальные агрегирующие операции: Women.objects.aggregate(res=Avg('cat_id')) или так: Women.objects.filter(pk__gt=4).aggregate(res=Avg('cat_id')) Здесь агрегация выполняется не для всех записей, а только для тех, у которых id больше 4. Метод valuesВо всех наших примерах выше, при выборке записей автоматически возвращались все поля. Если это была таблица women, то получали девять полей от id до cat_id. Но часто этого не требуется и достаточно ограничится несколькими нужными полями. Кроме того, такое ограничение положительно сказывается на скорости обращения к БД. Итак, для указания нужных полей в выборке, используется метод values() с указанием названий полей, например, так: Women.objects.values('title', 'cat_id').get(pk=1) На выходе имеем запись только с двумя полями. Причем, смотрите, если мы укажем взять данные из связанной таблицы для имени категории: Women.objects.values('title', 'cat__name').get(pk=1) то Django сформирует запрос с использованием оператора JOIN SQL-запроса. Если посмотреть коллекцию: connection.queriesто увидим следующее: SELECT "women_women"."title", "women_category"."name" FROM "women_women" INNER JOIN "women_category" ON ("women_women"."cat_id" = "women_category"."id") WHERE "women_women"."id" = 1 LIMIT 21 Благодаря такой конструкции одним запросом выбираются все нужные данные. Или, даже так: w = Women.objects.values('title', 'cat__name') При выполнении этой строчки пока ни один SQL-запрос выполнен не был, т.к. запросы в Django «ленивые», обращение к БД происходит только в момент получения данных. Но, если вывести список постов: for p in w: print(p['title'], p['cat__name']) то увидим, что для этой операции также был сделан всего один запрос. То есть, Django достаточно хорошо оптимизирует процесс обращения к БД. Группировка записей и агрегирование через метод annotateЧасто вызов агрегирующих функций применяется не ко всем записям, а к группам, сформированным по определенному полю. Например, в таблице Women можно сгруппировать записи по cat_id и получим две независимые группы записей. Затем, к каждой группе применить агрегацию и получить искомые значения. В качестве примера, давайте подсчитаем число постов для каждой группы категорий. Для этого запишем такую команду: Women.objects.values('cat_id').annotate(Count('id')) Ее действие графически можно представить так:
То есть, здесь группировка автоматически выполняется по единственному полю, которое мы выбираем из таблицы. Однако, выполняя ее, мы не видим ожидаемого результата. Почему? Если посмотреть последний SQL-запрос: connection.queriesто увидим, что группировка также выполняется по полям title и time_create. Это связано с тем, что в модели Women во вложенном классе Meta прописана сортировка по этим полям: ordering = ['-time_create', 'title'] Поставим эту строчку в комментарий, выйдем из оболочки Django, снова зайдем, импортируем необходимые модули: from women.models import * from django.db.models import * from django.db import connection и повторим команду: Women.objects.values('cat_id').annotate(Count('id')) Теперь видим две группы и для каждой подсчитано число статей. Мы можем изменить имя параметра id__count, скажем, на total, указав этот именной параметр: Women.objects.values('cat_id').annotate(total=Count('id')) Вот так можно группировать записи и вызывать для них с помощью метода annotate() нужную агрегатную функцию. Вообще, метод annotate() используется для вызова агрегирующих функций в пределах групп. Если не указывать никаких полей для группировки: Women.objects.annotate(Count('cat')) То получим просто все записи (так как группировка будет выполняться для всех полей). А вот если записать наоборот: Category.objects.annotate(Count('women')) то также получим все рубрики, но в каждом объекте списка будет атрибут: c = _ c[0].women__count содержащий число записей для текущей рубрики. Мало того, далее, мы можем прописывать другие методы, для отбора этих рубрик по значению агрегатной функции: c = Category.objects.annotate(total=Count('women')).filter(total__gt=0) Здесь отбираются все категории, в которых более нуля записей, то есть, есть хотя бы одна запись. Класс FВо всех предыдущих примерах мы делали выборки, указывая конкретные значения полей, например, так: Women.objects.filter(pk__lte=2) Но что если вместо 2 нужно прописать значение другого поля таблицы? Просто указать его не получится, например, такая запись: Women.objects.filter(pk__gt='cat_id') приведет к ошибке. Для этого нужно использовать специальный класс F, позволяющий нам выполнять подобные операции. Сначала мы его импортируем: from django.db.models import F И, далее, вместо двойки запишем класс F, допустим, с полем cat_id: Women.objects.filter(pk__gt=F('cat_id')) Получим все записи, кроме первой (с id=1). А SQL-запрос будет иметь вид: SELECT … FROM "women_women" WHERE "women_women"."id" > "women_women"."cat_id" Здесь условие «id > cat_id» как раз и было сформировано благодаря использованию F класса. Конечно, это такой искусственный пример, демонстрирующий работу F-класса. Часто подобные операции приходится делать, когда нужно увеличить, например, счетчик просмотра страниц. Если предположить, что в нашей таблице women есть поле views для числа просмотров, то при каждом посещении страницы, мы могли бы увеличивать его значение на 1, следующим образом: Women.objects.filter(slug='bejonse').update(views=F('views')+1) При посещении страницы со слагом 'bejonse' произойдет увеличение ее считчика на 1. Или, бывает удобно делать так. Сначала статья читается из таблицы (мы ее так и так должны отображать на HTML-странице): w = Women.objects.get(pk=1) А, затем, происходит изменение счетчика: w.views = F('views')+1 После сохранения, новое значение будет записано в таблицу БД. У вас здесь может возникнуть вопрос: а почему бы нам в данном случае не использовать операцию инкремента: w.views += 1 Скорее всего, так тоже сработает, но в документации по Django такой подход не рекомендуется. Здесь могут возникать неопределенности при одновременном получении одной и той же страницы разными пользователями. Тогда значение views будет увеличено только один раз, хотя просмотров было два. Класс F решает подобные коллизии. Организация вычислений на уровне СУБДФреймворк Django содержит набор функций, позволяющие выполнять вычисления, связанные с полями таблицы, на стороне СУБД. Полный их список можно посмотреть по ссылке: https://djbook.ru/rel3.0/ref/models/database-functions.html Фактически, здесь приведены обертки над функциями, которые выполняются СУБД. Этих функций достаточно много. Это и функции работы со строками, датой, математические функции и так далее. Использование этих функций является рекомендуемой практикой, т.к. СУБД оптимизировано для их выполнения. Конечно, все имеет свои разумные пределы и нужно лишь по необходимости прибегать к этому функционалу. Давайте для примера рассмотрим использование функции Length для вычисления длины строки. Первым делом нам нужно ее импортировать: from django.db.models.functions import Length И, затем, аннотируем новое вычисляемое поле, например, для заголовков статей: ps = Women.objects.annotate(len=Length('title')) В результате, на ряду со всеми стандартными полями, получим дополнительное поле len: for item in ps: print(item.title, item.len) По аналогии используются все остальные подобные функции. Raw SQLВ случаях, когда уровня ORM Django недостаточно, всегда можно перейти на уровень SQL-запросов и записать свой для конкретной используемой СУБД. Необходимость в этом возникает крайне редко, но, тем не менее, нужно знать о такой возможности. В простейшем варианте выполнить непосредственно SQL-запрос можно через метод: Manager.raw(<SQL-запрос>) Например, так: Women.objects.raw('SELECT * FROM women_women') На выходе получаем объект RawQuerySet, содержащий данные выборки. Давайте выведем ее в консоль через цикл for: w = _ for p in w: print(p.pk, p.title) Как видите, все достаточно просто. Причем, абсолютно тот же самый результат увидим и при использовании класса модели Category: w = Category.objects.raw('SELECT * FROM women_women') Здесь модель не имеет особого значения, мы с ее помощью просто обращаемся к менеджеру записей (objects), чтобы выполнить метод raw() для запуска SQL-запроса. Хотя сами объекты в списке w будут являться уже экземплярами класса Category. Поэтому, для обращения к таблице women лучше использовать модель Women. Вместо представленного простейшего запроса, можно записывать и другие, самые разные, гораздо более сложные. Если вы не знакомы с SQL-запросами, то в качестве базового материала можно посмотреть курс по SQLite, где я затрагиваю эту тему: https://www.youtube.com/watch?v=KXdiuTOEFGA Однако, метод raw() имеет несколько нюансов в своей работе. Первый из них – это «ленивое» исполнение запроса, то есть, отложенная загрузка информации до момента первого обращения к ней. Например, при выполнении команды: w = Women.objects.raw('SELECT * FROM women_women') никакого SQL-запроса выполнено не будет. До тех пор, пока мы не попытаемся что-либо прочитать из переменной w: w[0].pk увидим один выполненный запрос: connection.queriesВторой нюанс связан с тем, что при выборке конкретных полей в команде SELECT мы обязаны всегда указывать поле id, например, так: w = Women.objects.raw('SELECT id, title FROM women_women') Без id метод raw() выдаст исключение. Также, смотрите, несмотря на то, что мы указали в SELECT всего два поля, мы, тем не менее, через ссылку w можем обратиться к любому другому, например, так: w[0].is_published Здесь сработал механизм отложенной загрузки полей и при обращении к конкретному, не указанному ранее полю, происходит дополнительное обращение к БД для его получения. И, действительно, в списке запросов мы видим это: SELECT "women_women"."id", "women_women"."is_published" FROM "women_women" WHERE "women_women"."id" = 1 Как вы понимаете, это не лучшая практика и такого нужно избегать. Если у вас много постов и вы для каждого поля is_published будете так выбирать данные, то Django сгенерирует множество одиночных SQL-запросов для их чтения. Это может заметно и необоснованно нагрузить используемую СУБД. Следующий момент – это возможность передавать параметры в SQL-запрос. Например, если мы хотим выбрать запись по ее слагу, то нужно написать что-то вроде: Women.objects.raw("SELECT id, title FROM women_women WHERE slug='shakira'") Но здесь вместо 'shakira', обычно, используется некий параметр, в котором и хранится значение слага. Конечно, первое что приходит на ум, это объявить некую переменную: slug = 'shakira' и напрямую передать ее в SQL-запрос: Women.objects.raw("SELECT id, title FROM women_women WHERE slug='" + slug + "'") Однако, это прямой путь к SQL-инъекциям, когда злоумышленник вместо слага запишет фрагмент SQL-запроса и прочитает данные из БД. Поэтому правильно будет использовать механизм параметров в таких raw-запросах: Women.objects.raw("SELECT id, title FROM women_women WHERE slug='%s'", [slug]) Соответственно, в списке параметров можно указывать множество переменных и прописывать их в SQL-запросе. На этом мы завершим обзор этой объемной темы – ORM Django. Конечно, здесь я вам показывал лишь принцип использовать различных методов и рассказывал о нюансах их работы. Объять этот материал целиком – слишком амбициозная задача, да и напоминать такие занятия будут справочное руководство. В конце концов, для этого есть документация – наше все. Без нее при изучении и дальнейшем использовании Django – никуда. Ссылки на нее будут под этим видео. Курс по Django: https://stepik.org/a/183363?utm_source=proproprogs Видео по теме |