|
Структуры. Вложенные структурыПрактический курс по C/C++: https://stepik.org/a/193691?utm_source=proproprogs На этом занятии познакомимся с еще одним составным типом данных – структурами. Чтобы было понятно, о чем идет речь, давайте сразу приведу пример объявления простой структуры для хранения координат точек в трехмерном пространстве: struct tag_point { int x; int y; int z; }; Такая запись логически объединяет три переменные x, y, z целочисленного типа в одном новом составном типе данных под названием struct tag_point. То есть, чтобы объявить ту или иную структуру в программе, используется следующий синтаксис: struct [имя структуры]
{
Здесь под полями структуры понимаются переменные, записанные при ее объявлении. В нашем примере поля – это переменные x, y, z. В конце объявления структуры ставится точка с запятой. Обратите внимание, что объявление структуры – это описание нового составного типа в тексте программы. Не более того. Компилятор здесь не создает никаких переменных и не размещает их в памяти. Это, всего лишь, новый тип данных, подобно базовым типам char, int, double, ... . А раз у нас есть тип, значит, можно объявить переменную этого типа. Сделать это можно следующим образом: int main(void) { struct tag_point pt; return 0; } Мы объявили локальную переменную pt типа struct tag_point. В языке Си тип структуры обязательно включает в себя два слова: struct и имя структуры. В отличие от языка С++, в котором первое слово struct можно опускать. Итак, что из себя представляет переменная pt в памяти, то есть, на уровне машинных кодов? В действительности, структуры – это абстракция языка Си. В машинных кодах она, естественно, не существует. Поэтому когда мы объявляем переменную этого типа, то в памяти устройства выделяется нужный непрерывный участок из байт и все поля структуры (ее переменные) по порядку располагаются друг за другом:
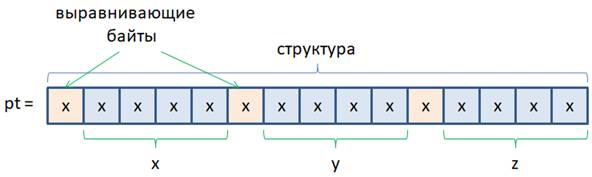
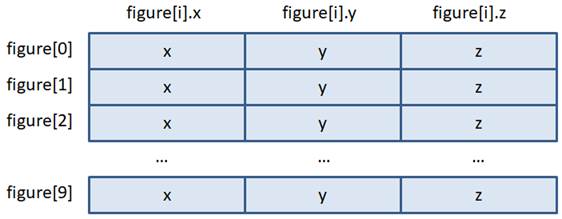
При этом в памяти, где размещаются поля структуры, компилятор может самостоятельно добавлять, так называемые, выравнивающие байты. Для чего это нужно? Дело в том, что чтение данных из оперативной памяти пакетом в две или четыре ячейки может происходить быстрее, если читаемые данные расположены по четным адресам. Например, это имеет место в интелловской архитектуре процессоров, а в некоторых других архитектурах данные размером в машинное слово или двойное машинное слово вообще строго обязательно размещать по четным адресам. Именно по этой причине компилятор может добавлять выравнивающие байты, чтобы переменные размером в машинное слово попадали в четные адреса. Этот процесс по-английски называется alignment – выравнивание. В результате, размер данных в структуре может превышать сумму размеров каждого из ее полей. И истинный размер можно получить с помощью знакомой нам операции sizeof следующим образом: size_t sz_pt = sizeof(pt); size_t sz_st = sizeof(struct tag_point); printf("sz_pt = %d, sz_st = %d\n", sz_pt, sz_st); После запуска программы получились значения 12: sz_pt = 12, sz_st = 12 То есть, в данном случае размер структуры в памяти равен сумме размеров трех целочисленных переменных int: 12 = 3 × 4 После того, как мы объявили переменную pt на структуру, ее можно заполнить конкретными значениями. Делается это следующим образом: pt.x = 1; pt.y = 2; pt.z = 3; То есть, пишется имя переменной, ставится точка и указывается имя поля, с которым мы собираемся работать. При этом запись pt.x или pt.y или pt.z – это уже отдельные целочисленные переменные типа int. И с ними мы работает как с обычными целочисленными переменными: присваиваем и считываем значения. Помимо присваивания отдельным полям тех или иных значений, структуры можно инициализировать подобно массивам. Для этого используется похожий синтаксис: <тип структуры> <имя переменной> = {[значения полей]}; В нашем примере инициализатор можно записать в следующих вариантах: struct tag_point pt = {10, 20, 30}; struct tag_point pt = {10}; struct tag_point pt = {}; В последнем случае наличие пустого инициализатора просто обнуляет значения полей. Стандарт С99 дополнительно вводит выделенные инициализаторы, которые позволяют задавать начальные значения полей по их именам следующим образом: struct tag_point pt = {.y = -1, .x = 2}; Вложенные структурыВообще в качестве полей структур можно использовать любые типы данных, в том числе, и другие структуры. Давайте вначале определим структуру для хранения имени и фамилии сотрудника: enum {name_length=50, b_length=20}; struct tag_fio { char name[name_length]; /* имя */ char last[name_length]; /* фамилия */ }; А, затем еще одну структуру для общих данных о сотруднике, включая его имя: struct tag_person { struct tag_fio fio; /* ФИО */ char sex; /* пол: м или ж */ unsigned short old; /* возраст */ char b_date[b_length]; /* дата рождения */ }; Как видите, здесь вторая структура имеет поле fio, которое является переменной первой структуры. Давайте теперь посмотрим, как можно инициализировать такие структуры и обрабатывать. Объявим переменную person на структуру struct tag_person со следующим инициализатором: int main(void) { struct tag_person person = { {"Sergey", "Balakirev"}, 'M', 98, "32.07.1925" }; return 0; } Далее, если нам нужно получить значения полей sex и b_date и вывести их на экран, то это можно сделать так: printf("sex: %c, b_date: %s\n", person.sex, person.b_date); То есть, мы также через операцию «точка» обращаемся к нужному полю по его имени и читаем данные. В итоге, person.sex – это переменная типа char, а person.b_date – одномерный массив символов. Давайте теперь изменим поля old и b_date. Сделать это можно следующим образом: person.old = 17; strcpy(person.b_date, "31.07.2006"); Обратите внимание, person.b_date – это одномерный массив типа char, поэтому для копирования в него новой строки нужно использовать функцию strcpy(), которая выполняет эту операцию. Просто присвоить одному массиву другой массив, как мы с вами уже говорили, нельзя: person.b_date = "31.07.2006"; // ошибка, так не работает Только с использованием строковых функций, о которых мы также с вами уже говорили. Хотя, в инициализаторе можно прописывать строковые литералы и они будут копироваться в соответствующие массивы. Но это отличия в работе инициализаторов и операции присваивания. А теперь самое главное, как обратиться к полям вложенной структуры? Думаю, многие из вас уже догадались. Сначала, конечно, нужно взять поле fio: person.fio Но это поле, в свою очередь, тоже структура с двумя своими полями name и last. Следовательно, после fio также нужно поставить точку и указать одно из этих полей, например, так: printf("name: %s, last: %s\n", person.fio.name, person.fio.last); Увидим строчку: name: Sergey, last: Balakirev Как видите, все предельно просто. Соответственно, если нужно изменить одно из полей вложенной структуры, то делается аналогично полю b_date, например: strcpy(person.fio.name, "Sergiy"); Копирование одной структуры в другуюБлагодаря тому, что структуры образуют полноценный тип данных языка Си, переменные одного и того же типа можно присваивать друг другу с копированием всей информации. Например, определим еще одну переменную типа struct tag_person: struct tag_person p; Тогда в нее можно скопировать всю информацию из переменной person того же типа с помощью обычной операции присваивания: p = person; Обратите внимание, здесь происходит именно копирование информации. На уровне машинных кодов область памяти, занимаемой структурой person, копируется в область памяти структуры p. В результате, все данные один в один копируются в структуру p. Поэтому, если вам нужно перенести данные из всех полей из одной структуры в другую, то лучше использовать обычное присваивание, чем по отдельности копировать поля. Это и быстрее и, кроме того, при изменении набора полей в структуре, в программе не понадобится вносить никаких изменений, что очень удобно. Давайте выведем некоторые поля переменной p и убедимся, что они не были изменены переменной person: printf("old: %d, b_date: %s\n", p.old, p.b_date); Увидим начальные значения: old: 98, b_date: 32.07.1925 Интересно, что массивы тоже можно было бы скопировать один в другой, если они прописаны внутри структуры. Например, пусть объявлена структура с одним одномерным массивом: #include <stdio.h> struct tag_array { int marks[b_length]; }; int main(void) { struct tag_array marks_1 = {2, 2, 2, 3, 2, 2}; struct tag_array marks_2; marks_2 = marks_1; for(int i = 0;i < sizeof(marks_2.marks) / sizeof(*marks_2.marks); ++i) printf("%d ", marks_2.marks[i]); return 0; } Смотрите, мы поместили одномерный массив в структуру, затем в функции main() объявили две переменные, одну из которых инициализировали, то есть, по сути, инициализировали элементы массива. Затем, второму массиву присвоили значения первого, данные были скопированы и цикл for их вывел в консоль: 2 2 2 3 2 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Получился довольно оригинальный способ работы с массивами. Хотя на практике так не делают. Объявлять структуру с массивом только ради возможности его копирования, не лучший ход. Если уж нам действительно так важно быстро перенести данные из одного массива в такой же другой, то для этого можно воспользоваться функцией: void* memcpy(void* restrict dst, const void* restrict src, size_t length); о которой мы с вами ранее уже говорили. Массивы структурВ заключение этого занятия отмечу такой очевидный момент, как объявление массивов из структур. Допустим, некоторая фигура описывается набором точек (вершин) в трехмерном пространстве. Для представления одной точки можно записать структуру: enum {max_points=10}; struct tag_point { double x, y, z; }; А, затем, использовать ее при объявлении массива: int main(void) { struct tag_point figure[max_points]; int figure_points = 0; // число точек в фигуре return 0; } В итоге получаем массив figure, каждый элемент которого является структурой типа struct tag_point:
Работать с этим массивом можно очевидным образом. Так как каждый его элемент figure[0], …, figure[9] является структурой, то, например, запись значений в его первые два элемента можно выполнить следующим образом: figure[0].x = 1.2; figure[0].y = -5.6; figure[0].z = 10.0; figure[1].x = 12.4; figure[1].y = 3.2; figure[1].z = 7.6; figure_points = 2; Подобным образом можно определять массивы из любых типов структур и работать с ними. Практический курс по C/C++: https://stepik.org/a/193691?utm_source=proproprogs Видео по теме |