|
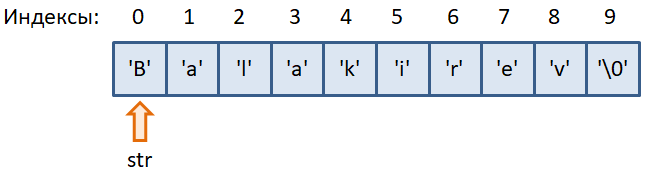
Строки. Способы объявления, escape-последовательностиПрактический курс по C/C++: https://stepik.org/a/193691?utm_source=proproprogs После знакомства с массивами в целом пришло время узнать, как в языке Си представлять строки и обрабатывать их. Сразу отмечу, что в Си нет строкового типа данных. Поэтому для хранения последовательности символов, как правило, используют массивы типа char. Например, так: #include <stdio.h> int main(void) { char str[] = {'B', 'a', 'l', 'a', 'k', 'i', 'r', 'e', 'v', '\0'}; return 0; } В итоге, в памяти устройства выделяется непрерывная область размером 10 байт, каждая ячейка которого содержит соответствующий символ строки:
Обратите внимание на последний символ ‘\0’. Он совпадает с числом 0. Это маркер (метка) конца строки. Его часто называют символом конца строки. Каждая корректная строка в языке Си должна иметь такой символ. Иначе, строка считается некорректной. Поэтому длина строки всегда на один больше общего числа «видимых» символов. Маркер конца строки не отображается стандартными функциями работы со строками, а лишь учитывается ими для определения конца строки. Вы заметили, как неудобно инициализировать массив отдельными символами? Поэтому для массивов типа char можно прописывать инициализатор в виде строкового литерала следующим образом: char s[] = "Sergey Balakirev"; Символ конца строки здесь добавляется автоматически. Явно указывать его не надо.
Чаще всего именно так на практике делают инициализацию массива строкой. Разумеется, при необходимости, в квадратных скобках можно указывать размер массива. Например, так: char buffer[512] = "Hello, World"; Тогда общий размер массива будет составлять 512 байт, а строка записана в первые 13 байт:
И вот здесь хорошо видна роль символа конца строки. Если бы его не было, то как бы мы поняли, что строка заканчивается на символе ‘d’? А не идет дальше, возможно, вплоть до конца массива? Но символ ‘\0’ нам четко и определенно указывает, где следует останавливаться. Разумеется, сама строка всегда начинается с самого первого элемента массива. Таким образом, для корректной строки мы всегда знаем, где она начинается и где заканчивается вне зависимости от общего размера массива типа char. Ту же самую строку в программе можно определить и несколькими литералами, записанных через пробельные символы: char b[] = "Hel" "lo" ", World"; Все эти фрагменты компилятор сначала соединит в один строковый литерал «Hello, World», а затем, при инициализации, занесет все эти символы в массив b. Или можно сделать так: char sp[] = "Hello, \ World"; Обратный слеш, за которым сразу следует символ переноса строки, компилятор воспринимает как продолжение описания строки. Соответственно, такое объявление сначала также будет представлено в виде строкового литерала «Hello, World» (обратите внимание, без переноса строки), а затем, им проинициализирован массив sp. Все эти варианты введены в язык Си исключительно для удобства оформления текста программы. Поэтому используйте тот, который внесет большую ясность при чтении программы. И еще раз подчеркну, что строки в языке Си объявляются исключительно в двойных кавычках. А элементы строк – символы – в одинарных кавычках. Например: char string[] = "a"; // строка из двух символов a0 char symbol = 'a'; // один символ буквы a Когда мы прописываем литерал в двойных кавычках, то компилятор формирует байтовый массив и в конец всегда автоматически добавляет символ конца строки ‘\0’. А когда прописываем одинарные кавычки, то это воспринимается как один символ (число с кодом указанного символа). Эти две записи нужно очень хорошо запомнить и правильно понимать. Представление строковых литералов в памятиВозможно, глядя на все эти вариации объявления строк, некоторые из вас задаются вопросом, а где и как все эти строковые литералы хранятся в процессе работы программы? В действительности, все что определено в двойных кавычках, представляется на уровне последовательности байт (условно, массива типа char) и физически сохраняется в выходном исполняемом файле. Затем, в момент загрузки, все эти строки размещаются в неизменяемой области памяти, как правило, в сегменте кода секции .text:
В результате, у каждого строкового литерала появляется свой уникальный адрес, который может быть использован при работе с соответствующей строкой. Именно так происходит при инициализации байтовых массивов: int main(void) { char s[] = "Sergey Balakirev"; char buffer[512] = "Hello, World"; return 0; } Компилятор передает в инициализатор адрес начала строки и в массив s выполняется копирование соответствующих символов, включая символ конца строки. То есть, области памяти, занимаемые массивом и строковым литералом, разные. Строка находится в неизменяемой области (ее нельзя менять в процессе работы программы), а массив размещается в стековом фрейме. Память под массив автоматически выделяется в момент вызова функции main(). Подробнее о стековом фрейме и других классах памяти мы с вами еще будем говорить. Но сразу отмечу, что несколько иная ситуация, когда мы задаем строку в глобальной области (вне функций), например, так: char buffer[512] = "Hello, World"; int main(void) { char s[] = "Sergey Balakirev"; return 0; } Тогда все начальные данные для соответствующих перемененных сохраняются в секции .data, затем, в момент загрузки программы сразу выделяется память под массив buffer и в эту область загружается строка "Hello, World".
Зачем я вам рассказываю все эти детали? Не все ли равно, где и как хранятся строковые литералы? Главное, чтобы мы могли их использовать в программе и достаточно! В большинстве случаев, так оно и есть. Но бывают ситуации, когда важно все это понимать. Например, что нам мешает объявить строку через указатель следующим образом: int main(void) { char* str = "Balakirev"; char s[] = "Balakirev"; return 0; } Чем будут отличаться эти два объявления? Сейчас, когда вы знаете, что строковые литералы размещаются в неизменяемой области памяти, а массивы – в стековом фрейме и лишь инициализируются строкой, можете догадаться, что через указатель str мы только можем читать символы строки, но не менять, а через массив s выполнять любые операции: и чтения и записи. Давайте проверим, так ли это? Попробуем изменить строковый литерал "Balakirev" через указатель str: str[0] = 'A'; После запуска программа завершается с ненулевым кодом, то есть, аварийно. Это, как раз, произошло из-за попытки внести изменения в неизменяемую область памяти. А вот с массивом s у нас такой проблемы не будет: s[0] = 'A'; Видим код завершения 0. По этой причине указатели на строковые литералы рекомендуется объявлять с ключевым словом const следующим образом: const char* str = "Balakirev"; Тогда уже на этапе компиляции будет выдана ошибка, при попытке изменения строки "Balakirev". А это гораздо лучше, чем потом гадать, почему программа вылетает. Кстати, в современных стандартах языка Си/С++ при объявлении таких указателей требуется прописывать ключевое слово const. Экранирование и спецсимволыДавайте снова вернемся к вопросу определения строк и представим ситуацию, когда нужно объявить строковый литерал вида: I like programming in "C" language. Сложность в том, что здесь внутри строки фигурируют двойные кавычки. Очевидно, прописать их просто так не получится. Попытка это сделать: char s[] = "I like programming in "C" language."; очевидно, приведет к синтаксической ошибке. Как же быть? Для этих целей предусмотрен механизм экранирования символов. Нам достаточно в строке перед каждой кавычкой прописать обратный слеш: char s[] = "I like programming in \"C\" language."; Обратный слеш указывает компилятору рассматривать символ двойной кавычки не как элемент синтаксиса языка, а именно как символ строки. В результате программа скомпилируется без ошибок, и массив s будет содержать нужную нам информацию. Вообще обратный слеш с разными символами ведет себя по-разному. Вот таблица наиболее употребительных сочетаний (escape-последовательностей):
Три символа из этой таблицы мы с вами уже использовали. Это \n, \" и \0. Остальные прописываются в строках аналогичным образом. Приведу лишь дополнительный пример с указанием символа в виде шестнадцатеричного кода: char str[] = "\x61 \x4f"; Это эквивалентно строке «a O». На этом мы завершим первое знакомство со строками. На следующем занятии продолжим эту тему и посмотрим, какие существуют встроенные средства для ввода/вывода строк из стандартных потоков. Практический курс по C/C++: https://stepik.org/a/193691?utm_source=proproprogs Видео по теме |