|
Переменные и их базовые типы. Модификаторы unsigned и signedПрактический курс по C/C++: https://stepik.org/a/193691?utm_source=proproprogs На прошлых занятиях мы с вами настроили рабочее место и разобрали структуру простой программы. Теперь, можно приступать к непосредственному изучению конструкций языка Си. Первое, с чего следует начать – это познакомиться со способами хранения данных. На уровне программы они могут быть представлены в двух видах:
Начнем с переменных. Как мы с вами уже говорили, данные в памяти компьютера хранятся в виде неделимых ячеек в один байт, которые образуют непрерывную последовательность определенной длины:
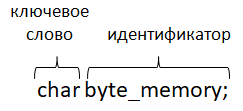
В современных компьютерах каждой запущенной программе отводится своя независимая рабочая область памяти. И адреса ячеек становятся уже не физическими, то есть, реальными, а логическими – теми, которые определит для программы ОС. Это сделано для повышения надежности работы сразу нескольких программ в один и тот же момент времени. Но нам, как программистам, важно лишь, что есть ячейки в один байт, каждая ячейка имеет свой адрес (логический или физический – не имеет большого значения) и все они следуют друг за другом в пронумерованном порядке. Причем, адреса всегда увеличиваются на единицу при переходе к следующей ячейке памяти. Так вот, в самом простом случае, мы можем в любую доступную для записи ячейку, поместить значение в виде целого числа из диапазона [0; 255]. Кратко напомню, что этот диапазон определяется тем, что один байт состоит из восьми бит, а каждый бит кодирует информацию двумя состояниями: 0 или 1. Получаем число возможных комбинаций 2^8 = 256. Значит, в один байт можно записывать произвольные целые числа в диапазоне от 0 до 255 включительно. Чтобы в программе на языке Си работать с отдельной ячейкой памяти, следует воспользоваться такой конструкцией: char byte_memory; Здесь char – это тип переменной; byte_memory – имя переменной. Именно так следует объявлять переменные в языке Си: сначала указывается тип данных для переменной, а затем, ее имя. На уровне синтаксиса это выглядит следующим образом: <тип переменной> <имя переменной>; Обратите внимание на точку с запятой в конце объявления переменной. Точка с запятой в языке Си является неотъемлемой частью оператора, а не разделителем между операторами, как иногда полагают. В данном случае символ точка с запятой указывает компилятору, где заканчивается операция объявления переменной и превращает запись в полноценный, законченный оператор. Далее мы с вами увидим, как символ точка с запятой входит в состав синтаксиса оператора цикла for и там она играет свою особую роль. А на данный момент нужно просто запомнить, что запись оператора объявления переменной (или нескольких переменных) должна завершаться точкой с запятой. Но вернемся к типу char. Он описывает хранилище данных размером в один байт и позволяет хранить 256 вариаций из целых чисел. А имя переменной – это, по сути, название хранилища, где расположено некоторое целое число.
На рисунке переменная byte_memory условно находится в 103-й ячейке памяти. В действительности, расположение переменных определяет менеджер памяти ОС. Когда в программе объявляется очередная переменная, то ОС располагает ее в найденной свободной последовательности ячеек. И, как вы понимаете, в общем случае, адрес хранения переменной может быть самым разным. Но на уровне программы для нас это не имеет особого значения. Мы всегда легко можем обратиться к хранилищу данных по имени переменной, прочитать или записать туда нужные значения. Делается это с помощью операции присваивания следующим образом: byte_memory = 100; char a; a = byte_memory; В конце каждого оператора ставится точка с запятой. Об операции присваивания мы с вами еще подробнее будем говорить. Здесь лишь отмечу, что в левый операнд заносится значение, записанное в правом операнде. То есть, при выполнении первой строчки, в переменную byte_memory будет занесено целое значение 100. В нашем случае, это автоматически означает, что ячейка с адресом 103 будет содержать число 100. В этом и есть смысл переменных: они могут менять свои значения в процессе выполнения программы. В двух следующих строчках происходит объявление еще одной байтовой переменной с именем a и копирование в эту переменную значения из переменной byte_memory. Обратите внимание, я употребил слово «копирование». Так как в языке Си переменные – это непосредственно хранилища данных, поэтому в момент присваивания происходит копирование информации из одного хранилища в другое. То есть, переменные a и byte_memory – совершенно независимы между собой. Я думаю, что вы в целом поняли, что из себя представляют переменные языка Си, как можно объявлять байтовые переменные, заносить и считывать из них данные. Дополнительно укажу лишь некоторые терминологические моменты.
Тип char относится к одному из ключевых, то есть, зарезервированных слов языка Си. В программе оно воспринимается компилятором исключительно как байтовый тип переменной и не может быть использовано в каком-либо другом качестве, например, как имя переменной. Далее, имя переменной также еще называют идентификатором, то есть, имя как бы идентифицирует область памяти, которую представляет. Забегая вперед, отмечу, что идентификаторами также являются имена функций и некоторых других конструкций языка Си. Применительно к имени переменной, в соответствии со стандартом С99, ее максимальная длина внутри модуля составляет 63 символа. Конечно, можно задавать имена и длиннее 63 символов, но компилятор будет учитывать только первые 63. Если же переменная используется за пределами модуля, где она объявлена, то ее максимальная длина составляет 31 символ. Это следует учитывать, хотя размер переменных более чем достаточен, чтобы не переходить указанные границы. Теперь, как правильно задавать имена переменных. Так как они представляют собой хранилища, то они должны быть существительными, например: data, name, total, count, size, fl_view и т.п. Следует иметь в виду, что язык Си различает большие и малые буквы в названиях переменных, да и вообще любых идентификаторов. Поэтому переменные: Comp, comp, COMP, cOmp - это разные переменные. В их именах можно использовать только символы латинского алфавита, цифры и символ подчеркивания: a-z, A-Z, 0-9, _ Причем, в качестве первого символа может идти или буква или символ подчеркивания. Цифра может появляться только, начиная со второго символа в названии переменной. Вот примеры правильных и неправильных имен:
Вообще, принято имена переменных записывать малыми буквами латинского алфавита без первого символа подчеркивания. Например, так: swift, book_si, text_array, counter и т.д. Именно такого написания я буду придерживаться в данном курсе. Думаю излишне говорить, что имена переменных должны быть уникальными в пределах одной области видимости. Базовые типы данныхИтак, мы с вами использовали базовый тип char, который описывает один байт памяти устройства. Конечно, в языке Си есть и другие встроенные типы данных. Они следующие:
Тип long long помечен оранжевым, так как он поддерживается не всеми компиляторами. В стандарте С99 были добавлены некоторые другие типы, но они не часто используются на практике, поэтому я не стал их приводить, чтобы не перегружать материал. Первое, что бросается в глаза, глядя на эту таблицу – это плавающий размер типов в зависимости от разрядности процессора и ОС. Да и они приведены лишь, как некий ориентир. В действительности стандарты языка Си никак не оговаривают конкретные размеры типов данных. А значит, компиляторы могут использовать такие, какие заложит в них разработчик. Конечно, большинство компиляторов согласуют размеры как в приведенной таблице. Но гарантии никакой нет. И, конечно же, здесь возникает закономерный вопрос: почему бы эти размеры строго не определить и договориться использовать вполне определенные значения? Но на это есть одно веское основание. Вспоминаем, язык Си разработан как заменитель языка Ассемблер и программы на Си должны наилучшим образом переводиться в машинный код. А машинный код жестко привязан к архитектуре компьютера: разрядности регистров процессора, шины и ячеек памяти. Например, тип char введен для работы с отдельными ячейками памяти. Если в компьютере они составляют 8 бит, то и компилятор будет описывать тип char восьмью битами. Если же представить вычислительную технику с ячейками в 12 бит, то логично тип char также сделать 12-битным. Вот почему размеры типов жестко не регламентируются спецификациями языка Си. И так со всеми остальными. Например, тип int – это основной среди целочисленных. Почему так? Потому что вплоть до появления 64-битных процессоров он совпадал по размеру с машинным словом процессора. Поэтому в эпоху 16-битных процессоров int составлял 16 бит (2 байта), при 32-битных – 32 бита (4 байта). А вот при появлении 64-битных он остался 32-битным. Опять же, казалось бы, давайте его по логике увеличим до 64 бит? Но здесь возникла другая проблема. Если int сделать 64-битным, то у нас не будет целочисленного типа в 32 бита. Вводить новый было бы неразумно, т.к. существует масса ранее уже написанных программ с использованием только таких типов данных. А компиляторы стараются создавать так, чтобы программы на Си были переносимыми, то есть, чтобы их можно было впоследствии перекомпилировать под другую платформу или для другого процессора. Все это и обусловливает такую неопределенность типов данных. Но одно мы все же можем сказать. Относительное распределение размеров типов следующее: char <= short <= int <= long <= long long float <= double <= long double Но более ни на что рассчитывать не приходится. Хотя, как я уже сказал, большинство компиляторов для стандартной вычислительной техники, придерживаются размеров, указанных в таблице. Итак, примем как данность неопределенность размеров типов и будем ориентироваться на данные из таблицы. В ней мы видим еще такую запись: short [int] или long [int] или long long [int] Что означает int в квадратных скобках? Это значит, что формально эти типы можно записывать как с int в конце, так и без него, например: short int a; short b; long d; long int m; Причем, от добавления слова int тип данных никак не меняется, поэтому в современной практике программирования на Си это ключевое слово совместно с модификаторами short и long не указывают, а пишут просто: short b; long d; Зачем тогда вообще появились эти сочетания short int, long int? Все это пришло из глубокой древности языка Си. Вероятно, Деннис Ритчи изначально задумывал один общий целочисленный тип int и два модификатора к нему: short и long, чтобы иметь возможность определять более короткие и длинные по размеру памяти целочисленные переменные. Но, так как short и long, кроме как к целочисленным переменным не применяется (кроме, разве что long double, который появился позже), то особого смысла дописывать int просто нет. Модификаторы signed и unsignedВообще подобные «неряшливые» моменты время от времени встречаются и их нужно правильно понимать и учитывать при написании программ, особенно, когда программа пишется под заказ. Поэтому важно отметить еще одну такую «неряшливость», связанную с типом char. Когда мы в программе задаем переменную этого типа: char fl_view; то в зависимости от компилятора она может принимать или целые числа в диапазоне [0; 255], или целые числа в диапазоне [-128; 127]. Стандартом это также никак не оговорено. Откуда взялись эти диапазоны? Первый (от 0 до 255) – это, по сути, беззнаковое представление целого числа в одном байте. А второй – это те же 256 вариаций, но для представления целых чисел со знаком. Спрашивается, как же нам в программе гарантированно описать переменную fl_view как беззнаковую или, наоборот, как знаковую? Для этого в языке Си существуют два модификатора:
Если при объявлении явно указать: unsigned char fl_view; то переменная fl_view будет описывать целые числа в интервале [0; 255]. Если же указать: signed char fl_view; то переменная fl_view будет описывать целые числа со знаком в интервале [-128; 127]. А теперь, внимание! Все остальные целочисленные типы (short, int, long, long long) по умолчанию всегда идут как знаковые. Поэтому определение вида: int arg; создает переменную arg как целочисленную и знаковую. И так со всеми другими типами, кроме char. Кстати, именно по этой причине в языке Си появился модификатор signed, чтобы гарантированно объявлять переменную типа char со знаком. У других целых типов модификатор signed указывать не имеет смысла, он идет по умолчанию. А вот второй модификатор unsigned вполне имеет смысл. Например: unsigned short d; Получаем целочисленную беззнаковую переменную с именем d. И так со всеми целыми типами. Обратите внимание, когда я говорю о модификаторах signed и unsigned, то отмечаю именно целочисленные типы данных. Дело в том, что вещественные типы float и double всегда знаковые и применять к ним эти модификаторы нельзя. Рекомендации по выбору типов для переменныхИтак, перед нами множество самых разных типов переменных. Спрашивается, как ориентироваться в этом многообразии и выбирать наиболее подходящий вариант? На этот счет есть довольно простые рекомендации. Если нам требуется хранить отдельные символы или работать с отдельными ячейками памяти, то для этого существует только один тип char. Если предполагается оперировать целочисленными значениями, то изначально следует подумать о типе int. Этот тип нам может не подойти в двух ситуациях: если мы создаем в программе большое число целочисленных переменных (от 1000 и более), то следует посмотреть в сторону типа short в целях экономии памяти. Конечно, тип short можно использовать, только если его диапазона значений достаточно для представления данных в рамках решаемой задачи. Иначе, придется опять же обратиться к типу int, или даже типу long. Типы long или long long (если его поддерживает компилятор) следует использовать только в случае, если диапазон значений int недостаточно. Наконец, для описания вещественных чисел (чисел с плавающей точкой), следует изначально рассматривать тип double. И обращаться к типу float только если в программе предполагается создавать много вещественных чисел (от 1000 и более). Тип long double практически не используется за редким исключением сложных математических вычислений. Итак, по результатам этого занятия вы должны хорошо себе представлять, как выбирать имена переменных, какие базовые типы данных существуют в языке Си и какого они бывают размера (в битах или байтах), как объявлять переменные и как правильно применять модификаторы signed и unsigned. Практический курс по C/C++: https://stepik.org/a/193691?utm_source=proproprogs Видео по теме |