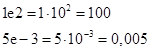|
Операция присваивания. Числовые и символьные литералы. Операция sizeofПрактический курс по C/C++: https://stepik.org/a/193691?utm_source=proproprogs На этом занятии подробнее рассмотрим операцию присваивания, а также числовые и символьные литералы. Начнем с операции присваивания. На предыдущем занятии мы с вами научились объявлять переменные. Например, так: #include <stdio.h> int main(void) { int var; return 0; } Создается целочисленная переменная с именем var внутри функции main. Так как мы не присваивали ей пока никакого значения, то она будет содержать произвольные данные. Давайте следующей строчкой занесем в целочисленное хранилище var значение 100. Сделать это можно с помощью операции присваивания, которая в языке Си определена символом равно: var = 100; Обратите внимание, я говорю операция присваивания, а не оператор. Дело в том, что в языке Си присваивание реализовано как выражение и помимо копирования данных эта операция еще возвращает скопированное значение. В данном случае – это целое число 100. И только благодаря точки с запятой, записанной в конце, компилятор понимает, где заканчивается данная конструкция и начинается следующая. То есть, точка с запятой превращает операцию присваивания в оператор – завершенную конструкцию языка Си. Как я уже отмечал на предыдущем занятии, операция присваивания копирует значение из правого операнда в левый операнд. Соответственно левый операнд должен явно или косвенно определять ячейки памяти, куда можно занести значение, указанное в правой части. Как говорят в программировании, слева должно стоять модифицируемое лево-допустимое выражение (l-value). В простейшем случае – это просто имя переменной. Но могут быть и другие конструкции, с которыми мы познакомимся в будущем. Учитывая, что присваивание это операция, мы могли бы записать ее и в таком виде: int var, size; size = var = 100; Смотрите, во-первых, в программе объявляются две целочисленные переменные, которые перечисляются через запятую после типа данных int. Так тоже можно делать и это вполне распространенная и допустимая практика объявления сразу нескольких переменных одного и того же типа. Во-вторых, в следующей строчке присваивается целое значение 100 сразу двум переменным. Такая запись допустима, как раз благодаря тому факту, что присваивание является операцией, а не законченным оператором. Вначале число 100 будет присвоено переменной var, а затем, возвращенное значение 100 присваивается переменной size. Точка с запятой в конце завершает эту конструкцию и определяет ее как оператор. Конечно, эту же программу мы могли бы записать и так: int var, size; var = 100; size = 100; Современные компиляторы в обоих случаях сформируют оптимальный машинный код и корректно переведут эту программу в наборы машинных инструкций. Поэтому, какой вариант присваивания использовать решает сам программист, исходя из удобства оформления программы. Сразу же отмечу еще один важный момент, связанный с объявлением переменных. Правило хорошего тона предполагает, что все значимые переменные следует объявлять вначале каждого блока операторов (то есть, фигурных скобок). А уже затем, выполнять операции с ними. Именно так сделано в нашей программе: сначала идет объявление двух переменных, а ниже описаны действия с ними. Благодаря этому упрощается понимание и редактирование программ. При необходимости, каждую переменную можно сопроводить поясняющим комментарием. Конечно, это относится только к значимым переменным. Любые другие, временные, можно объявлять в любом месте программы, чтобы визуально она не засорялась лишними деталями. Инициализация переменныхВ языке Си, равно как и во многих других языках высокого уровня, можно определять значение переменной сразу в момент ее объявления. Например, так: int total = 1024; Визуально это выглядит как обычное присваивание переменной значения. Но в действительности – это совершенно другая операция, которая называется инициализацией переменной. То есть, когда мы объявляем какую-либо переменную (любого типа) и сразу указываем для нее некоторые начальные данные, то в этот момент запускается механизм инициализации этой переменной. Компилятор четко различает эти две ситуации: инициализация и обычное присваивание. На уровне машинных кодов они также могут быть реализованы по разному. Да и синтаксически, как мы в будущем увидим, при инициализации возможные конструкции, которые нельзя использовать при присваивании. А пока на данном этапе достаточно знать и запомнить, что есть процесс инициализации переменных, а есть присваивание данных и, в общем случае, это разные вещи. Для полноты картины приведу еще один пример, когда мы комбинируем обычное объявление и инициализацию переменных: int total = 1024, buffer; Синтаксически так тоже можно делать и использовать в своих программах. Целочисленные и символьные литералыТеперь давайте внимательнее посмотрим на число 100 в нашей программе. И зададимся вопросом, как его воспринимает компилятор и где оно хранится? В программировании явно прописанные числовые значения называются числовыми литералами и представляется как целочисленная константа типа int. Почему именно типом int? Так решил создатель языка Си Деннис Ритчи: все целочисленные константы, записанные в программе в десятичном виде, хранить на уровне типа int. Но только в том случае, если число умещается в диапазон этого типа. Напомню, что в современных 32- и 64-битных компьютерах тип int, как правило, составляет 4 байта (32 бита) и описывает диапазон значений: [-2147483648; 2147483647] Если целочисленный литерал положителен и не умещается в этот диапазон, то компилятор подбирает соответствующий размер типов данных в порядке возрастания: int, unsigned int, long, unsigned long, long long, unsigned long long Если же и самого большого недостаточно (что сложно себе представить в реальных задачах), то компилятор выдаст ошибку. Но так только с целыми числами, записанными в десятичном виде. Язык Си позволяет определять в программе числовые литералы еще в шестнадцатеричной и восьмеричной форме. Делается это очень просто, например: int dec, hex, oct; dec = 100; hex = 0x1FA; oct = 0123; Здесь 100 – это десятичная форма записи; 0x1FA – шестнадцатеричная (число 1FA); 0123 – восьмеричная. То есть, для записи шестнадцатеричных чисел перед ними ставится префикс в виде символов «0x», а для записи восьмеричных – префикс в виде нуля. Так можно прописывать любые числа в нужном нам формате. Разумеется, на уровне машинных кодов они представляются единым образом в виде набора бит и запись числовых литералов в той или иной форме служит исключительно для удобства восприятия программистом. Не более того. Но с шестнадцатеричными и восьмеричными литералами есть один важный нюанс. Их компилятор изначально представляет не типом int, как десятичные, а типом unsigned int. Соответственно, если литерал не умещается в этот тип, то берутся другие больших размеров в порядке: unsigned int, unsigned long, unsigned long long При желании мы можем явно указать компилятору тип числового литерала. Для этого используются следующие суффиксы:
Обычно в программах прописывают большие буквы L, так как малые случайно можно спутать с изображением числа 1. Суффикс U можно записывать и отдельно, но можно комбинировать с суффиксами L и LL: int dec_i, dec_ui, dec_l, dec_ul; dec_i = 100; // тип литерала int dec_ui = 100U; // тип литерала unsigned int dec_l = 100L; // тип литерала long dec_ul = 100UL; // тип литерала unsigned long Хорошо, с запись литералов разобрались. Но как они сохраняются непосредственно в программе? Конечно же компилятор переводит их в машинный код и хранит непосредственно в скомпилированной программе как неизменяемые данные, то есть, как константы. Когда программа загружается в память компьютера, то вместе с ней загружаются все данные, которые мы явно определяем в тексте. Отлично, с этим разобрались. Давайте теперь посмотрим на тип char, который формально определен и как символьный и как целочисленный. Первый вопрос, как такое может быть? На самом деле все очень просто. Объявим переменную этого типа, например: char ch; а, затем, присвоим ей какой-либо символ, например, буквы d: ch = 'd'; Обратите внимание, как прописан символ в тексте программы: он заключен в одинарные кавычки (их еще называют апострофами). И только так можно определять символьные литералы в языке Си. Когда компилятор видит одинарные кавычки, то он воспринимает информацию в них, как символ. Никакие другие кавычки для этого использовать нельзя. Например, двойные зарезервированы для определения строк, поэтому запись: ch = "d"; приведет к ошибке на этапе компиляции. Если же совсем убрать кавычки, то символ d в программе будет восприниматься как переменная: ch = d; Поэтому следует запомнить, что для определения символьного литерала используются только одинарные кавычки. Хорошо, на уровне программы мы теперь знаем, как прописывать отдельные символы. Но спрашивается, как эти символы представляются в машинных кодах. Там же могут быть только числа. Все верно. И это очень важный момент. Все символьные литералы в программе автоматически переводятся в соответствующие коды. Как я вам уже говорил на самом первом занятии, каждому символу ставится в соответствии определенный код (целое число). И приводил фрагмент таблицы ASCII. Так вот, компилятор, используя текущую кодовую таблицу (не обязательно ASCII), переводит все числа в соответствующие коды. В частности, символ буквы ‘d’ в нашем случае имеет код 100. Любой другой символ будет иметь другой код. И, по сути, строчка программы: ch = 'd'; в нашем конкретном случае, может быть заменена на: ch = 100; Хотя, явно прописывать так не следует, потому что при другой кодовой таблице код символа d может быть другим. Далее, мы можем вывести это значение переменной ch с помощью функции printf() в двух форматах: символьном и числовом: printf("ch = %c, code = %d\n", ch, ch); Об этой функции мы еще подробнее будем говорить, пока только отмечу, что вместо символов «%c» будет подставлено значение ch и переведено в символ. А вместо «%d» будет также подставлено также значение из ch, но выведено в виде целого десятичного числа. После запуска программы увидим: ch = d, code = 100 Этот факт показывает, что компьютеру важно лишь какое число хранится в переменной ch, а его интерпретация может быть самой разной: или как символ, или как целое число. Причем, обратите внимание, компилятор преобразовывает символьные литералы в числа типа int, а не char, как можно было бы ожидать. Это, как раз связано с тем, что он воспринимает любой символ, как десятичное число, а оно по умолчанию представляется типом int. Конечно, при работе с символами мы формально можем использовать любой другой целочисленный тип. Например, прописать так: int ch; ch = 'd'; В данном случае на работу программы это никак не повлияет. Но, все же, если планируется в переменных хранить коды символов, то лучше использовать тип char в целях экономии памяти, т.к. этого типа достаточно для представления всех основных символов, включая и русские буквы. Вещественные литералыПомимо целочисленных в программе можно прописывать и вещественные литералы. Определять их можно следующими способами: double d1, d2, d3, d4; d1 = 10.0; d2 = -7.; d3 = 1e2; d4 = 5e-3; В первых двух случаях используется символ точки. Причем, обратите внимание, несмотря на то, что числа 10.0 и -7.0 с математической точки зрения соответствуют целым числам 10 и -7, на уровне программы они будут вещественными и иметь тип double. Все вещественные литералы компилятор языка Си по умолчанию представляет этим типом данных. Соответственно, математические операции с числами 10.0 и -7.0 будут выполняться несколько иначе, чем с аналогичными целыми числами. Это следует иметь в виду. Последние два варианта – запись числа в экспоненциальной форме: <число>e<степень десятки> Например, запись:
Такую форму удобно использовать в научных расчетах, когда используются или очень маленькие или очень большие числа. В любом случае экспоненциальная форма переводится в вещественное число типа double, даже если оно математически является целым, а не дробным. При желании мы можем явно указать компилятору переводить вещественный литерал в тип float. Для этого после числа следует прописать суффикс f, например, так: d1 = 10.0f; В такой записи вещественное число 10.0 будет представляться типом float, а не double. Это бывает полезно, когда используется переменная типа float и ей правильно было бы присвоить значение того же типа: float var_f; var_f = 10.0f; Тогда компилятор не выдаст предупреждение (warning) о возможной потере данных в момент присваивания значения переменной var_f. Операция sizeofВ заключение этого занятия отмечу довольно распространенную операцию sizeof языка Си. Она возвращает число байт, занимаемых в памяти переменной или, отведенных под тип данных. Синтаксис этой операции следующий: sizeof(<тип | имя переменной>); sizeof <имя переменной>; Обратите внимание, во втором случае мы можем записать ключевое слово sizeof без круглых скобок, но тогда эта операция применяется только к переменным, но не к типам. Чтобы не запоминать эти тонкости, обычно sizeof записывают с круглыми скобками и указывают либо тип данных, либо имя переменных. Например: int size_float = sizeof(float); int size_var_f = sizeof(var_f); На выходе получаем число байт, которое занимает тип float и переменная var_f. Соответственно: int size_ch = sizeof(char); всегда равно единице. ЗаключениеИтак, на этом занятии вы должны хорошо понимать, как работает операция присваивания и инициализация переменных в языке Си. Знать, как записываются и представляются на уровне машинных кодов числовые и символьные литералы, а также какие суффиксы у них можно пописывать. И, конечно же, уметь применять операцию sizeof для определения размера типа данных или переменной. Практический курс по C/C++: https://stepik.org/a/193691?utm_source=proproprogs Видео по теме |